
Se tem uma coisa que tira as noites de sono dos desenvolvedores de smart contracts são as taxas de transações. Isso porque um smart contract com altas taxas tem baixo incentivo aos usuários utilizarem-no de fato. Aprender como reduzi-las é uma habilidade que vale ouro neste mercado e muitos serviços de consultoria que já prestei eram justamente sobre isso.
Em outra oportunidade eu expliquei aqui no blog como as taxas funcionam e é imprescindível que você tenha este conhecimento antes de avançar. Neste artigo eu quero te dar diversas dicas de como reduzir as taxas do seu contrato. E também na parte 1 eu trouxe as PRINCIPAIS técnicas, aquelas que trazem o maior ganho possível, sendo que nesta parte 2 vou entrar em otimização menores e mais pontuais, que farão mais diferença em contratos complexos ou com muitos acessos.
Importante frisar que para alguns testes visando pegar a economia real das otimizações, eu usei o toolkit HardHat com a função estimateGas, sendo que fornecerei os fontes completos dos testes para vocês ao final do artigo, em um formulário. Abaixo, a função compare que usei para comparar as otimizações e imprimir no terminal com formatação:
|
1 2 3 4 5 6 7 8 9 10 11 |
const compare = (bad: bigint, good: bigint) => { console.table({ Bad: bad.toString(), Good: good.toString(), Saving: `${bad - good} (${((good * 100n) / bad) - 100n}%)`, }); expect(bad).to.greaterThanOrEqual(good); }; |
Isso vai gerar saídas como abaixo.
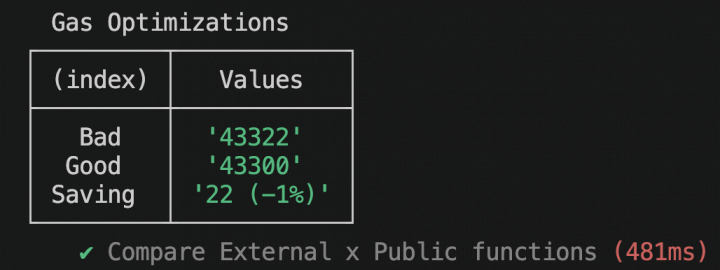
Atenção: os testes todos são bem simples então os custos serão sempre baixos. No entanto, atente ao fato de que é comum funções apresentarem vários dos cenários descritos a seguir que poderiam ser otimizados, gerando então uma economia real. Além disso, funções chamadas de maneira repetida também obtém ganhos superiores quando analisadas no volume total ao invés de individual. Ainda assim, estamos falando de otimizações menores, sendo que as maiores foram trazidas na parte 1.
Vamos lá!

#1 – Otimizações Sintáticas
Eu chamo de otimizações sintáticas aquelas advindas do uso correto dos elementos da linguagem Solidity, como modificadores, tipos e funções nativas. Dos três grupos de otimizações que vou tratar nesse tutorial, este é aquele que produz o menor impacto por otimização, mas ao mesmo tempo é aquele que depois de “enraizado” na sua cabeça, é o mais fácil de usar no dia a dia.
Se preferir, você pode assistir ao vídeo abaixo ao invés de ler este bloco.
external x public
As palavras reservadas external e public podem, à primeira vista, parecer gerar o mesmo resultado, mas isso é um engano. Uma function external SOMENTE pode ser chamada de fora do contrato, enquanto que uma function public pode ser chamado dentro e fora. E essa diferença gera 22 gás de diferença em cada transação e pode ser usado quando a função realmente só será chamada externamente. Segue o fonte do contrato:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
contract ExternalXPublic { uint x = 0; function testExternal() external { x = 1; } function testPublic() public { x = 1; } } |
E segue o fonte do teste, que é muito parecido em todos os testes que vamos fazer, por isso não vou ficar repetindo:
|
1 2 3 4 5 6 7 8 9 10 11 |
it("Compare External x Public functions", async function () { const ExternalXPublic = await ethers.getContractFactory("ExternalXPublic"); const contract = await ExternalXPublic.deploy(); const badCost = await contract.testPublic.estimateGas(); const goodCost = await contract.testExternal.estimateGas(); compare(badCost, goodCost); }); |
revert x require
Tanto a função nativa revert quanto a require servem ao propósito de lançar um erro no caso de uma condição não atendida. Aliás, internamente o require é um if + revert, não havendo diferença entre ambos, a MENOS QUE você use custom errors, como detalhado neste artigo de 2021 do blog do Solidity. Se você usar custom errors você terá além de benefícios de code design, melhor eficiência no gás usado se comparado com a error string do require.
Assim, no exemplo abaixo, as primeiras duas funções são equivalentes, enquanto que a terceira abordagem performará melhor. Infelizmente não consegui extrair métricas apuradas por causa do lançamento de erro que quebra os cálculos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
contract RevertXRequire { uint x = 0; function testRequire(uint number) public { require(number < 10, "CustomError"); x = 1; } function testRevert(uint number) external { if(number > 10) revert("CustomError"); x = 1; } error CustomError(); function testRevertCustom(uint number) external { if(number > 10) revert CustomError(); x = 1; } } |
Agora se testarmos o cenário de sucesso dessas funções, o custo de gás é sempre menor quando usamos if + revert ao invés de require, de 19 a 41 gás nos exemplos acima, com e sem custom error.
storage x memory x calldata
As três diferentes formas de armazenamento de dados são um assunto recorrente quando falamos de otimização de smart contracts, afinal, é justamente por causa de armazenamento em storage que temos transactions e consequentemente custo de transação. Isso se dá porque storage é o único armazenamento permanente, enquanto que memory e calldata só ficam salvos durante a execução da transação, sendo limpos depois e por isso são usados para parâmetros de funções. Mas o quanto é essa diferença de fato?
A diferença é de 490 gás no contrato abaixo quando usamos calldata ao invés de memory. Isso acontece porque calldata é somente leitura, ficando em uma área de memória ainda mais “leve” que memory, que permite escrita.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
contract StorageXMemoryXCalldata { string x = ""; function testMemory(string memory text) external { x = text; } function testCalldata(string calldata text) external { x = text; } } |
Assim, a regra é:
- variável de estado (do contrato), permanente? storage
- parâmetro somente leitura? calldata
- parâmetro leitura e escrita? memory
- variável interna da função? memory (a não ser que o tipo não permita, aí é storage)
Agora se o parâmetro for um array, a diferença se torna ainda maior se usar memory onde deveria ser calldata. Só o fato do array memory ser passado (0 elementos) aumenta o custo em 416 gás + 228 gás para cada elemento existente no array em comparação com o mesmo array passado via calldata, como abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 |
uint y = 0; function testArrayMemory(uint[] memory numbers) external { y = numbers[numbers.length - 1]; } function testArrayCalldata(uint[] calldata numbers) external { y = numbers[numbers.length - 1]; } |
Isso se deve ao fato de que por padrão, os parâmetros vem como calldata, mas se memory for especificado, eles têm de ser copiados para memory a fim de que possam ser alterados (escrita).
Validação x modifier
Esse é contra intuitivo e não julgo quem faz “errado”. Entre aspas porque na verdade nem tudo se resume a otimização de taxas, certo? Quando queremos impedir por exemplo o acesso de uma função a somente um endereço específico, podemos fazê-lo de duas formas: ou usamos require/revert dentro da função em questão ou criamos um custom function modifier, certo?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
contract ValidacaoXModifier { address admin = 0xf39Fd6e51aad88F6F4ce6aB8827279cffFb92266; uint x = 0; error CustomError(); function testValidacao() external { if (msg.sender != admin) revert CustomError(); x = 10; } modifier isAdmin(){ if (msg.sender != admin) revert CustomError(); _; } function testModifier() external isAdmin() { x = 10; } } |
A diferença nesse caso é que fazer a validação dentro da própria função economiza 22 gás, referentes à chamada de função isAdmin adicional no caso do uso com modifier. Note que acima já estou usando o que há de mais econômico em termos de validação, que conforme vimos antes é if + revert, se estiver sem essa otimização a diferença pode ser ainda maior.

#2 – Otimizações Lógicas
Eu chamo de otimizações lógicas aquelas advindas do ajuste da lógica de parte do seu algoritmo a fim de obter benefícios em performance sem perder em nada a funcionalidade original. Embora elas não sejam tão “mecânicas” de se fazer como as do grupo anterior, elas podem produzir efeitos muito maiores.
Se preferir, você pode assistir ao vídeo abaixo, o conteúdo é o mesmo deste tópico.
Quantidade de Escritas
Uma coisa que pode parecer óbvia mas que muitas vezes erramos sem querer é exagerar nas escritas no storage. Você deve sempre ter em mente que toda vez que realiza uma atribuição a uma variável de estado, uma escrita no storage é realizada e que isso é um dos maiores consumos de taxas que você pode ter no seu contrato. Assim, sempre que sua função tiver um loop, JAMAIS escreva no storage dentro desse loop, olhe o exemplo abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
contract OtimizacoesLogicas { uint x = 0; function multiplasEscritas() external { for (uint i = 0; i < 10; i++) x += i; } function umaEscrita() external { uint local = 0; for (uint i = 0; i < 10; i++) local += i; x = local; } } |
Embora a segunda função seja maior em número de linhas, variáveis, etc, ela performa muito melhor que a primeira, com 4236 gás a menos! E obviamente esse valor escala ad infinitum conforme a complexidade do que está sendo feito dentro do loop, então fique de olho!
Quantidade de Leituras
Ok, é óbvio que escrever no storage é a ação mais custosa, mas ler no storage também não é algo que deve ser feita de maneira frívola, e vou te provar. Considere as funções abaixo, onde na primeira fazemos várias leituras no storage, uma a cada iteração do loop. Na segunda, eu guardo localmente após fazer uma única leitura e as demais comparações são feitas em cima da variável local. A diferença? São 909 gás a menos na segunda abordagem, e olha que estamos lidando apenas com primitvas (uint) e um laço pequeno (10 iterações).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
uint y = 0; function multiplasLeituras() external { for (uint i = 0; i < 10; i++) { if (y > 0) y = 1; } x = 1; } function umaLeitura() external { uint local = y; for (uint i = 0; i < 10; i++) { if (local > 0) y = 1; } x = 1; } |
Novamente o alerta aqui é: viu loop? Tome cuidado!
Evitando cópia de Structs
Structs são um poderoso elemento do Solidity para criação de estruturas de dados mais complexas, mas como são armazenadas no storage, já viu né! Aqui vou dar duas dicas baseadas nesse elemento sintático. A primeira é sobre evitar a cópia de structs inteiras para memory, quando você quer pegar apenas um ou outra informação, como abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
contract LidandoComStructs { struct Book { string title; string author; uint year; } mapping(uint => Book) books; constructor(){ books[1] = Book({ title: "Test", author: "Test", year: 2024 }); } string x = ""; function testBadStruct() external { Book memory book = books[1]; x = book.title; } function testGoodStruct() external { x = books[1].title; } } |
Repare que na primeira função eu pego um livro do mapping, copio ele pra memória e pego apenas o título. Na segunda, eu acesso o livro e já pego seu título, sem a cópia completa da struct do storage para a memória. O ganho neste exemplo foi de 5348 gás na segunda abordagem, considerando aquela struct simples, com poucos e pequenos dados.
Structs em Laços
Claro, este exemplo anterior foi de uma struct sendo copiada inteira para a memória, mas mesmo nos casos em que você for acessar apenas uma propriedade sem a cópia, convém copiar o valor dessa propriedade (se repetida) para uma variável local, como abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
function testLoopAStruct() external { for (uint i = 0; i < 10; i++) { if (books[1].year > 3000) break; } x = "finish"; } function testLoopBStruct() external { uint local = books[1].year; for (uint i = 0; i < 10; i++) { if (local > 3000) break; } x = "finish"; } |
Simplesmente o segundo exemplo performa igual consumindo 1709 a menos de gás, isso com esse código simples e apenas 10 iterações.

#3 – Otimizações Algorítmicas
Eu chamo de otimizações algorítmicas aquelas advindas da reescrita quase total de um algoritmo, muitas vezes mudando seu comportamento normal em prol de ganhos de performance e taxas. Para encerrar este artigo de hoje, vou citar uma otimização algorítmica bem famosa entre quem trabalha com projetos NFT. Via de regra, o padrão mais popular para NFTs é a ERC-721, que já estudamos aqui no blog em outra oportunidade e não há nada de errado com o padrão em si, ele atende bem ao que se propõe.
No entanto, conforme o mercado de NFTs foi evoluindo, viu-se que este padrão possuía um enorme gargalo quando o assunto era mintar múltiplas NFTs, o que desencoraja esse tipo de atitude entre os clientes por causa das taxas exorbitantes. Isso acontecia porque esse padrão acabava tendo inúmeras validações e controles que crescem de custo linearmente, ou seja, quanto mais NFTs você quer mintar, mais caro fica.
Pensando em resolver isso, a empresa Azuki fez uma otimização significativa no algoritmo mais popular do padrão, fornecido pela OpenZeppelin, criando o padrão não-oficial ERC721a, que torna o custo de mintar múltiplas NFTs logarítmico, conforme tabela abaixo.
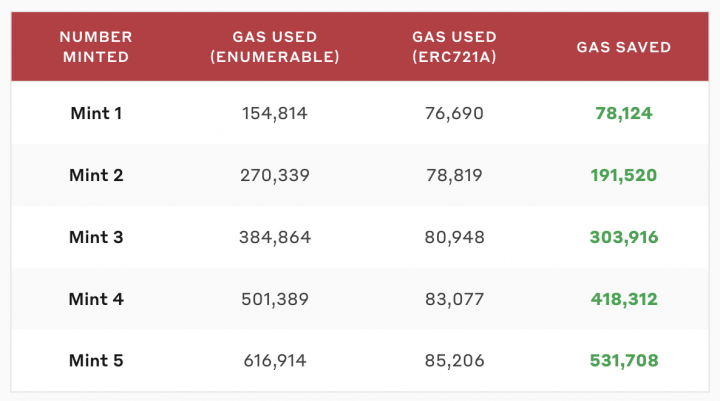
Eu não vou entrar em detalhes aqui de implementação do padrão pois ele é bem extenso e tem um tutorial dedicado a isso aqui no blog. Apenas gostaria de ressaltar que diversas otimizações, algumas inclusive citadas aqui por mim ao longo dessa série de artigos, foram utilizadas para chegar nesses números impressionantes, mostrando em situações reais, otimizações combinadas podem levar a ganhos surpreendentes.
Até a próxima!





Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.