
Se tem uma coisa que tira as noites de sono dos desenvolvedores de smart contracts são as taxas de transações. Isso porque um smart contract com altas taxas tem baixo incentivo aos usuários utilizarem-no de fato. Aprender como reduzi-las é uma habilidade que vale ouro neste mercado e muitos serviços de consultoria que já prestei eram justamente sobre isso.
Em outra oportunidade eu expliquei aqui no blog como as taxas funcionam e é imprescindível que você tenha este conhecimento antes de avançar. Neste artigo eu quero te dar diversas dicas de como reduzir as taxas do seu contrato.
Vamos lá!

#1 – Complexidade de Algoritmos
A primeira coisa que você tem de entender é que quanto mais complexo o seu algoritmo, em termos de processamento e espaço, mais ele vai custar para ser executado. Eu abordo em detalhes essa dica no vídeo abaixo, caso prefira assistir ao invés de ler.
Via de regra, sempre que ver um loop no seu código Solidity, muita atenção. Geralmente os loops são os maiores vilões das taxas. Se você aprender a usar corretamente arrays e mappings, é possível que jamais precise de um laço na sua vida de programador Solidity. Ao menos não em transações pelo menos.
Como isso é possível? Considere o seguinte código Solidity abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
struct Book { uint id; string title; uint16 year; } contract MyContract { Book[] books; function updateBook(uint id, string calldata newTitle) public { for(uint i=0; i < books.length; i++){ if(books[i].id == id){ books[i].title = newTitle; break; } } } } |
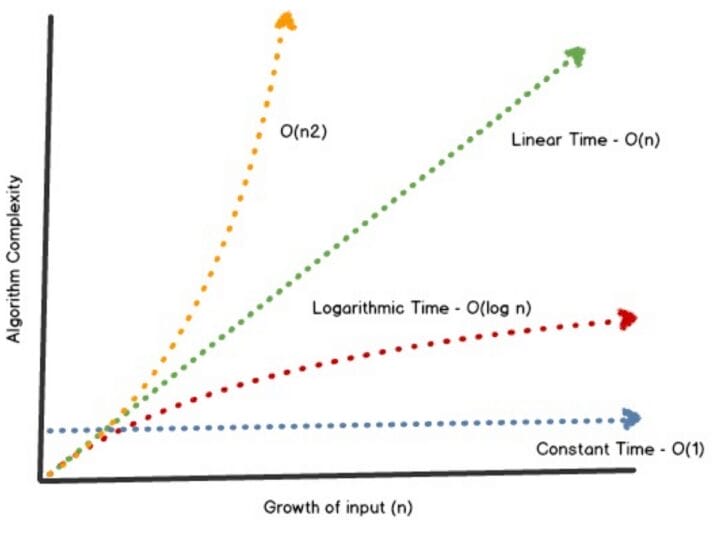
Temos um array de livros e uma função para atualizar o título de um deles. Qual a complexidade dessa função no pior cenário? Eu respondo: O(n), onde n é o número de elementos no array. Ou seja, complexidade linear: quanto mais o array crescer, mais caro se tornará executar essa função.
Mas agora olhe essa abordagem abaixo, usando um mapping como índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
contract MyContract { Book[] books; mapping(uint => uint) bookIndex;//id to index function updateBook(uint id, string calldata newTitle) public { uint index = bookIndex[id]; books[index].title = newTitle; } } |
Isso reduz a complexidade de O(n) para O(1), ou seja, de linear para constante. Não importa o tamanho do array, sempre vai levar o mesmo tempo para atualizar um livro. Claro, manter esse mapping com os livros vai exigir um pouco mais de gasto na escrita inicial do livro na blockchain, mas ainda assim, considerando que ela é feita apenas uma vez e também tem complexidade O(1) (push no array e adição no mapping), isso não é um problema.
E este é apenas um exemplo, quando se estuda complexidade de algoritmos se abre todo um leque de otimizações que em cenários comuns fazem você ganhar tempo, mas que em Solidity o fazem economizar muito dinheiro também.
Agora se você realmente precisar fazer um laço, usar do/while ao invés de for faz você economizar 3.000 gás se você tem certeza que vai precisar de ao menos uma execução no laço. Mas se precisar realmente usar um for, usar ++i ao invés de i++ no for gera 1.000 gás de economia, já que o i++ lê o valor atual e depois incrementa, enquanto que ++i apenas incrementa). Fica a dica.
Se você nunca estudou complexidade de algoritmos antes, o vídeo abaixo traz uma boa introdução sobre análise assintótica, que é a forma mais comum de analisar e expressar complexidade, independente da linguagem de programação, requisitos de hardware, etc.

#2 – Redução de Armazenamento
Falamos sobre processamento na dica anterior e como reduzi-lo reduz também os custos das transações. Mas e espaço no storage? No vídeo abaixo falo sobre esta dica, caso prefira assistir ao invés de ler.
Ler e armazenar informações no storage estão entre os opcodes mais caros de realizar pela EVM, olhe a tabela abaixo.
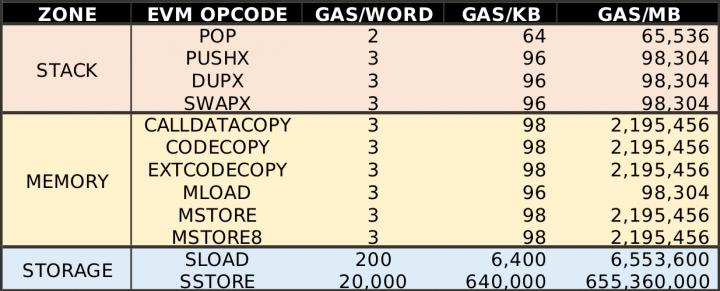
Um SLOAD custa 6.400 gás por KB e um SSTORE custa 100x mais!!!
Assim, quanto menor forem as variáveis de estado, ou seja, os dados que precisarão ser lidos e escritos no contrato, melhor!
Pensando nisso vou dar algumas dicas de armazenamento de maneira geral, antes de entrar na otimização das variáveis em si. A primeira é nunca, sob hipótese alguma, salvar arquivos na blockchain. Imagens de NFT, ícones de moedas, fotos de documentos…isso não deve estar na blockchain. Na blockchain armazene somente referências a esses arquivos, como hash, URL, etc. Sobre os arquivos em si, caso deseje armazená-los de maneira descentralizada e imutável, a recomendação é a rede IPFS, que é como se fosse uma blockchain de arquivos, que apresentei no vídeo abaixo.
Essa é a solução mais comum para mídias de NFTs, por exemplo, pois economiza muito espaço e consequentemente taxas. Subimos primeiro as mídias das NFTs para a rede IPFS e obtemos o CID (hash) de cada uma. Aí incluímos o CID no arquivo JSON de metadados da coleção e subimos esse arquivo para IPFS, referenciando somente o CID dele no contrato da coleção.
Outra dica ligada para reduzir o armazenamento de muitos dados está ligada ao deploy. Em grandes projetos é comum termos vários contratos, o que eventualmente nos leva a funcionalidades semelhantes ou até código repetido entre eles. Por uma questão de boa prática e também pensando em economizar no deploy, costuma-se utilizar libraries Solidity para isso.
Libraries são arquivos Solidity apenas com funções, structs e outros elementos independentes que você pode fazer deploy na blockchain como se fosse um contrato e irá receber o endereço da mesma. Durante o desenvolvimento, você deve ter uma cópia local desse arquivo e importá-lo normalmente em seu código, como abaixo, onde tenho uma library com uma struct compartilhada:
|
1 2 3 4 5 6 7 8 9 10 |
pragma solidity ^0.8.20; library JKPLibrary { struct Player { address wallet; uint32 wins; } } |
E que depois eu importo no contrato principal, para usar esta struct:
|
1 2 3 4 5 6 7 8 |
import "./JKPLibrary.sol"; contract JoKenPo { JKPLibrary.Player[] public players; //... |
Nesta etapa o ganho não envolve qualquer economia de taxas, mas sim de reuso de código. Na hora do deploy sim que você terá ganho uma vez que sua library já esteja na blockchain (tenha sido feito o deploy antes). Por exemplo a library famosa SafeMath, uma biblioteca com funções seguras para cálculos matemáticos, neste link. De posse do endereço da library, você pode referenciá-la no deploy do contrato principal, para o Solidity saber quando fizer o carregamento do contrato na EVM para execução, onde está a “outra parte” dele. Abaixo exemplo de script de deploy passando o endereço da library:
|
1 2 3 4 5 6 7 8 |
const MetaCoin = await ethers.getContractFactory("MetaCoin", { libraries: { SafeMath: "0x...", }, }); const metaCoin = await MetaCoin.deploy(); |
Apesar do deploy ser feito apenas uma vez, as suas taxas costumam ser elevadas conforme o tamanho do contrato. Então a dica geral aqui é: bora diminuir o tamanho do seu contrato!

#3 – Otimizações de Código
Nesta categoria de reduções possíveis temos a mais vasta em quantidade de dicas e também onde há o menor custo x benefício por dica. Muitas vezes uma otimização no código traz sim uma redução de taxas, mas tão ínfima que pode ser considerada irrelevante para a maioria dos contextos. Então quer dizer que é inútil otimizar código Solidity? Claro que não é isso que estou dizendo, apenas que deve ser sua última preocupação a menos que o seu cenário seja de alta complexidade (mesmo considerando tudo que aprendeu no passo 1) ou que lide com grandes quantidades de dados (mesmo considerando tudo que aprendeu no passo 2).
Ainda assim, ao invés de fazer uma lista extensa de micro-ajustes que são difíceis de lembrar e que economizam pouco gás, vou tentar propor algumas melhorias maiores. A primeira delas é na compilação do seu código.
O Solidity Compiler (solc) possui um parâmetro de otimização que por padrão vem desabilitado. Esse parâmetro, quando ligado, permite dizer ao compilador que otimize o seu código para taxas menores nas transações ou para tamanho menor no deploy. Mas é um ou outro. Ou deixa desligado. Isso não é sempre possível, mas geralmente provoca diferenças sim em contratos grandes e é possível graças às diferentes formas que o compilador pode combinar de opcodes para chegar no resultado que você deseja com seu algoritmo. Sabe o lance de usar i++ vs ++i, pois é, é esse tipo de otimização, mas de maneira automática.
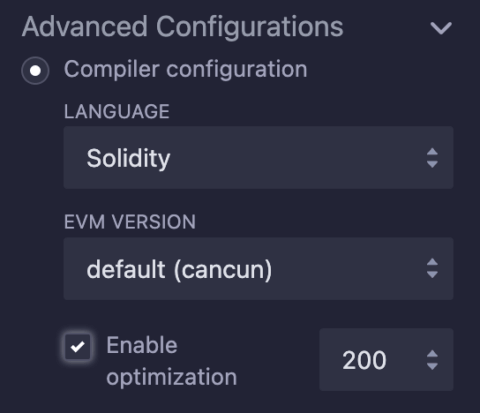
Se estiver utilizando o Remix, essa opção pode ser habilitada no menu Solidity Compiler, seção Advanced Configurations, como mostra a imagem abaixo onde marquei o checkbox “Enable optimization”.
Se estiver usando o HardHat, esta configuração você pode habilitar no hardhat.config, sendo abaixo um exemplo com esta configuração nos valores default (se você não preencher, é dessa forma que vai estar):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
const config: HardhatUserConfig = { solidity: { version: "0.8.20", settings: { optimizer: { enabled: false, runs: 200 } } } }; |
Agora no momento que você setar o enabled do optimizer para true, a propriedade runs será usada para aumentar ou diminuir a otimização, sendo 200 o valor comum (“otimiza pouco”). Procurando na Internet encontrei o valor de 1000 para otimizar bastante focando em transações mais baratas, mas aumentando o custo de deploy e o valor de 20 para otimizar bastante para deploy barato, aumentando o custo de transações.
Mas por que não deixamos isso sempre ativado e no máximo, já que diminuir custo de transações é sempre uma ideia? Além dos tempos maiores de build, deixar o otimizador no máximo tende a aumentar os bytecodes do seu contrato, encarecendo o deploy mas não só isso: como a EVM tem limite de bytes por transação, um build com muitos bytecodes pode esbarrar nesse limite ao tentar fazer o deploy. Outro problema de deixar o otimizador sempre ligado é que ele atrapalha o desenvolvimento já que o código-fonte que você vai estar desenvolvendo não será o mesmo que será testado, gerando problemas de debug e coverage por causa das numerações de linha diferentes.
Agora trazendo para a linha de escrita de código mais eficiente mesmo, vamos falar de variáveis de estado, as terceiras maiores vilãs de taxas depois de complexidade de algoritmo e armazenamento de dados. Assim como tratamos no item 2, a leitura e armazenamento no storage são grandes vilões das taxas e uma vez que as variáveis de estado sempre são lidas ou escritas do storage, isso acaba as tornando vilãs indiretas também. A seguir vou falar de storage slots, se preferir, pode assistir ao vídeo abaixo sobre o mesmo tópico.
Uma das primeiras coisas que aprendemos é que é importante escolher o tipo certo para nossas variáveis. E isso não está errado, mas é uma meia verdade. Segue abaixo as dicas mais comuns e depois explico algo tão importante quanto isso:
- se é numérico >0, use uint ao invés de int;
- sempre use o menor tamanho numérico onde caiba o número máximo que precisar armazenar (uint8 para 0-255, uint16 para 0-65.535, etc);
- se são apenas dois valores possíveis, prefira boolean;
- prefira bytes32 ao invés de string;
- se o valor não muda, use immutable ou constant (trocando SLOAD por PUSH32 economiza 2097 gás);
- se é enumerável ou pesquisável, use array, se é acesso aleatório por chave, use mapping;
- só defina a variável como public em último caso;
O que não te explicam geralmente é que não adianta você se preocupar com os itens acima se não entender algumas outras coisas como por exemplo o que acontece quando mandamos salvar um dado no storage do contrato, o comando SSTORE.
O storage é organizado em storage slots, blocos de armazenamento em disco com 256-bit de tamanho. Quando esse slot esgota ou quando o que você deseja salvar é maior que ele, um novo comando SSTORE é chamado para alocar mais 256-bit e salvar o novo dado. Olha esse exemplo:
|
1 2 3 4 5 |
uint128 x = 0; uint256 y = 1; uint128 z = 2; |
É um exemplo bobo, mas o que vai acontecer aqui? Vão ser usados 3 storage slots ao invés de 2, porque ao tentar escrever a segunda variável não vai haver espaço suficiente, e ao tentar escrever a terceira, não vai haver espaço de novo. Se você reorganizar assim, vai ter 33% de economia de gás na escrita dessas três variáveis:
|
1 2 3 4 5 |
uint128 x = 0; uint128 z = 2; uint256 y = 1; |
Então pensa na escrita do seu código como se fossem blocos em um jogo tipo Tetris. Não basta escolher os tipos certos se jogar eles de qualquer jeito no código, essa técnica de organização é chamada de Variable Packing e afeta não somente a escrita, mas também a leitura pois o SLOAD também carrega em chunks de 256-bit.
Ainda dentro desse contexto você reparou que eu inicializei as três variáveis de estado? Sempre inicialize elas, mesmo que seja com o valor default pois isso gera 40% de economia quando for escrever sobre ela novamente no futuro pois já terá alocado espaço suficiente já no deploy.
Existem centenas de outras otimizações de código que você pode aplicar quando o assunto são as suas functions Solidity. Mas como esse artigo já está muito extenso, deixarei elas para a parte 2, toda dedicada a micro otimizações, ok?
Lembrando que o principal que você deve ter cuidado são esses três tópicos acima. Se aplicar bem eles, as próximas melhorias que vou trazer serão apenas a cereja do bolo, então até lá!






Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.