

Em 2008, mais ou menos, eu estava fazendo as cadeiras de Banco de Dados 1 e Banco de Dados 2 na faculdade de Ciência da Computação. Eu via como modelar um banco de dados relacional, como criar consultas e executar comandos SQL, além de álgebra relacional e um pouco de administração de banco de dados Oracle.
Isso tudo me permitiu passar a construir sistemas de verdade, com persistência de dados. A base em Oracle me permitiu aprender o simplíssimo MS Access rapidamente e, mais tarde, migrar facilmente para o concorrente, SQL Server. Posteriormente cheguei ainda a trabalhar com MySQL, SQL Server Compact, Firebird (apenas estudos) e SQLite (para apps Android).
Todos relacionais. Todos usando uma sintaxe SQL quase idêntica. Isso foi o bastante para mim durante alguns anos. Mas essa época já passou faz tempo. Hoje em dia, cada vez mais os projetos dos quais participo têm exigido de mim conhecimentos cada vez mais poliglotas de persistência de dados, ou seja, diferentes linguagens e mecanismos para lidar com os dados das aplicações.
Antes de entrar em persistência poliglota, deixa eu perguntar uma coisa: considere uma caixa de ferramentas com alicate, martelo e chave de fenda, qual é a melhor ferramenta de todas?

A resposta mais coerente é: depende. Se você tem de apertar um parafuso, a chave de fenda. Quando tem de pregar um prego, o martelo. Para cada atividade, existe uma ferramenta adequada.
Avançando rumo à persistência poliglota, uma coisa que demorei a entender é que NoSQL não é melhor do que SQL. Lembra? Um martelo não é, necessariamente, melhor que uma chave de fenda.
Da mesma forma, embora muitas vezes a impressão que tenhamos é que bancos não-relacionais são sempre melhores do que os relacionais (tem muita empresa e curso que vende isso como verdade), não é assim que funciona. ACID tem o seu valor e muitos não-relacionais não se focam nisso, simplesmente porque não é esse o problema que querem resolver.
Existem diversos cenários em que você DEVE usar bancos SQL tradicionais, seja por questões legais (auditorias, certificações ou necessidades mais elementares), e cenários em que você PRECISA usar bancos não-relacionais. Jamais migre o SQL da sua empresa para um NOSQL pois ele parece mais cool ou porque todos estão falando de como ele é mais rápido. Isso é DOM – Desenvolvimento Orientado à Modinhas, e não é isso que estou propondo aqui.
O primeiro passo é entender o seu problema. O segundo passo é analisar as opções para resolvê-lo.
Se preferir, ao invés de ler este post você pode assistir ao meu vídeo abaixo.
Passo 1: entenda o seu problema
Está com problema de performance no seu banco SQL? Já pensou em dar uma olhada nestas minhas dicas aqui de SQL Server e nestas aqui de SQLite? Já pensou em fazer um upgrade no hardware do seu servidor? Botar mais memória, um SSD de repente?
Garanto que isso é muito mais fácil, rápido e barato do que migrar todo o seu banco para um NOSQL que você nem conhece direito. Trocar de SQL para NOSQL sem pensar, na maioria dos casos, é trocar os problemas antigos que você conhecia por problemas novos que você não faz ideia de como resolver.
Passo 2: analise as opções
Agora, se o modelo entidade-relacionamento não está servindo, aí sim você começa a pensar em NOSQL. Daí sim entramos no passo de analisar as opções.
Uma opção é desenvolver o seu próprio mecanismo NOSQL, como eu fiz com o Busca Acelerada (e que aliás está no ar até hoje, enquanto não termino a nova versão com Node.js + MongoDB), como o Facebook fez com o Cassandra, como o Google fez com o Big Table e assim por diante. Mas, sinceramente, é meio difícil acreditar que alguma das dezenas de opções de NOSQL disponíveis atualmente não atendam a sua necessidade. É só uma questão de conhecer as opções e analisá-las com cuidado.
Faça o que eu digo, não faça o que eu fiz!
Pra ajudar, vou mostrar algumas excelentes opções a seguir. De nada! 😉
Para cada problema, uma solução
Existem dezenas de bancos NoSQL no mercado, não porque cada um inventa o seu, como nos fabricantes tradicionais de banco SQL (não existem diferenças tão gritantes assim entre um MariaDB e um MySQL atuais que justifique a existência dos dois, por exemplo). É apenas uma questão ideológica, para dizer o mínimo.
Existem dezenas de bancos NOSQL porque existem dezenas de problemas de persistência de dados que o SQL tradicional não resolve. Simples assim. Claro, também temos algumas classificações entre eles, pois resolvem problemas em comum, geralmente com abordagens diferentes. É provável que isso seja cada vez mais frequente conforme estas ferramentas se tornem mais populares (pouco se ensina nas faculdades ainda, por exemplo).
Não, eu não conheço todos. E sim, vou falar de algumas ferramentas de persistência aqui que nunca usei, mas que presenciei o uso em projetos ou conheço pessoas/empresas que usam. Novamente: não use nenhum deles porque acha que eu indiquei, mas sim porque resolvem o seu problema em questão.
Mas, voltando ao que interessa, é comum classificarmos os bancos NOSQL em algumas categorias:
- Armazenamento em Documentos
Estes são os mais comuns e mais proeminentes de todos, sendo o seu maior expoente o banco MongoDB, que eu já falei aqui no meu blog nos posts sobre Node.js e em uma série de posts específicas pra ele. Basicamente aqui temos coleções de documentos, nas quais cada documento é autossuficiente, contém todos os dados que possa precisar, ao invés do conceito de não repetição + chaves estrangeiras do modelo relacional.
A ideia é que você não tenha de fazer JOINs, pois como já comentei em outro post, eles prejudicam muito a performance em suas queries (são um mal necessário no modelo relacional, infelizmente). Vai uma vez no banco e com apenas uma chave primária pega tudo que precisa.
Obviamente isto tem um custo: armazenamento em disco. Não é raro bancos MongoDB consumirem muitas vezes mais disco do que suas contrapartes relacionais.
Mas quando eu preciso de um MongoDB?
Quando o seu schema é variável, é livre. Os documentos BSON (semelhante ao JSON) do Mongo são schema-less e aceitam quase qualquer coisa que você quiser armazenar, sendo um mecanismo de persistência perfeito para uso com tecnologias que trabalham com JSON nativamente, como Javascript.

Quando eu não devo usar um MongoDB?
Quando relacionamentos entre diversas entidades são importantes para o seu sistema. Se for ter de usar chaves estrangeiras e JOINs, você está usando do jeito errado, ou, ao menos, não do jeito mais indicado. Aqui tem um post bem bacana falando disso, sensacionalista, mas bem completo.
Outro mecanismo bem interessante desta categoria é o RethinkDB, que foca em consultas-push real-time de dados do banco, ao invés de polling como geralmente se faz para atualizar a tela.
Para os amantes de .NET tem o RavenDB, que permite usa a sintaxe do LINQ e das expressões Lambda do C# direto na caixa, com curva de aprendizagem mínima.
Mais uma adição para seu conhecimento: Elasticsearch. Um mecanismo de pesquisa orientado a documentos poderosíssimo quando o assunto é pesquisa textual, foco da ferramenta. Ele é uma implementação do Apache Lucene, assim como Solr e Sphinx, mas muito superior à esses dois e bem mais popular atualmente também.
Quer aprender muito mais sobre MongoDB? Dá uma conferida no meu livro sobre o assunto clicando no banner abaixo:

Ou então, assiste ao vídeo abaixo onde falo mais sobre este fantástico banco de dados não-relacional. Aproveite!
- Armazenamento Colunar
O maior expoente nesta categoria é o Cassandra, criado pelo Facebook. A maior rede social do mundo rapidamente percebeu que manter uma base de 1.5 bi de usuários criando milhares de registros todos os dias (likes, posts, fotos, amizades, etc) e depois ter de consultar tudo isso de maneira rápida e coerente, fazendo muitas agregações, não era uma tarefa que cabia aos bancos relacionais.
O armazenamento colunar, ao invés de guardar tabelas com linhas onde cada linha possui colunas, faz o inverso. Guardamos “tabelas” (não sou nenhuma autoridade no assunto) onde temos informações de apenas uma coluna de cada registro.
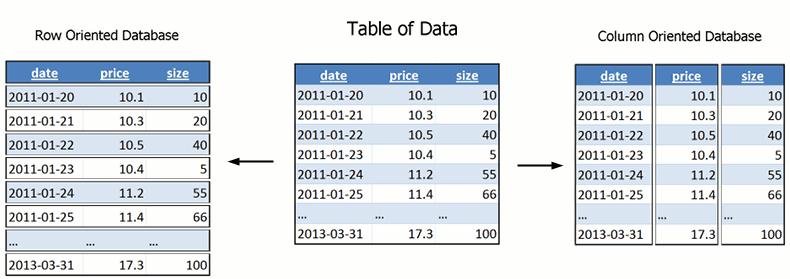
Mas quando eu preciso de um Cassandra?
Quando você faz muitas operações de agregação em suas colunas. Sabe o GROUP BY do SQL tradicional? Ela é outro mal necessário, assim como os JOINs, e tem uma performance ridiculamente baixa, principalmente associado com um WHERE complexo. Isso não é problema para uma base colunar, e um problema gigantesco para uma base orientada a documentos como o MongoDB, aliás.
Quando eu não devo usar um Cassandra?
Quando você precisa que suas consultas retornem dados completos ao invés de apenas informações colunares. Se isso for a regra, você deveria usar um relacional (meio-termo) ou um baseado em documento, como o Mongo (com registros “full-data” independentes).
Outra adição a esta seção é o HBase, escrito em Java e modelado a partir do BigTable do Google (este último proprietário e por isso não vale a pena citar aqui).
3 Armazenamento Chave-Valor
Estes bancos não-relacionais são o mais distante que você pode imaginar de um “banco de dados”, por isso que chamamos de mecanismos de persistência de dados, ao invés de “banco”. Vamos pegar como exemplo o Redis, o mais famoso mecanismo de chave-valor da atualidade (tutorial aqui). Se preferir, você pode assistir ao vídeo abaixo sobre Redis para entender melhor.
Aqui temos uma arquitetura baseada em coleções de chaves. Cada registro possui uma única chave, até aqui tudo normal, mas cada chave está associada a um valor, que pode ser um valor literal, atômico, ou um objeto mais complexo, não importa. É um índice, geralmente sendo usado memory-only, mas que pode ser híbrido também (disco e memória).
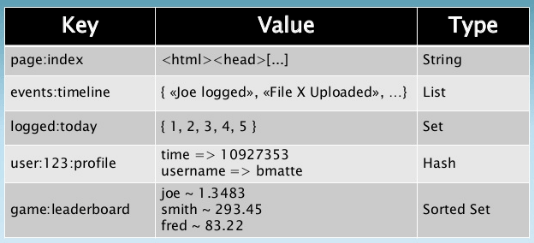
Mas quando eu preciso de um Redis?
Quando você precisa subir um índice em memória que seja estupidamente rápido, que permita queries complexas baseadas na teoria dos conjuntos e que, após essa consulta no índice, você vá usar alguma outra base de dados com os dados completos do(s) registro(s) que está buscando.
Quando eu não devo usar um Redis?
Você não deve usar como único mecanismo de persistência na sua aplicação, pois se subir todos os seus dados para um Redis memória você não terá alguns benefícios de outros modelos e gastará muito, mas muito dinheiro, pagando por memória RAM (muito mais cara que SSDs, por exemplo). Use-o como cache de índices. Ponto.
Concorrentes válidos de citar são o memcached e MemcacheDB, popular mecanismo de cache in-memory usado na web e, mais recentemente, em conjunto com MySQL para proporcionar algumas vantagens do modelo não-relacional em adição às suas nativas.
4 Arquitetura em Grafos
O modelo entidade-relacionamento é muito bom quando o assunto é garantir que os relacionamentos entre as entidades seja seguido, mas fraquíssimo quando o assunto são relacionamentos complexos ou relacionamentos com propriedades.
Como assim? E as tabelas-meio?
Sim, elas são a solução para esse caso, uma solução bem ruim aliás, pois nos força a usar JOINs o tempo todo e bem, a essa altura você já deve saber que eu não curto muito JOINs…
O que acontece se a relação entre o registro do Huguinho e do Zezinho tiver o tempo que eles são amigos, o grau de parentesco entre ambos, ou pior, os filmes que eles gostam em comum ou os amigos que possuem em comum? Como fazer isso com um banco relacional?
Claro que dá, mas e como fica a performance das consultas depois? E os INSERTs? O mais famoso banco em grafo da atualidade é o Neo4J, e é ele que deveria ser aplicado nesse caso.
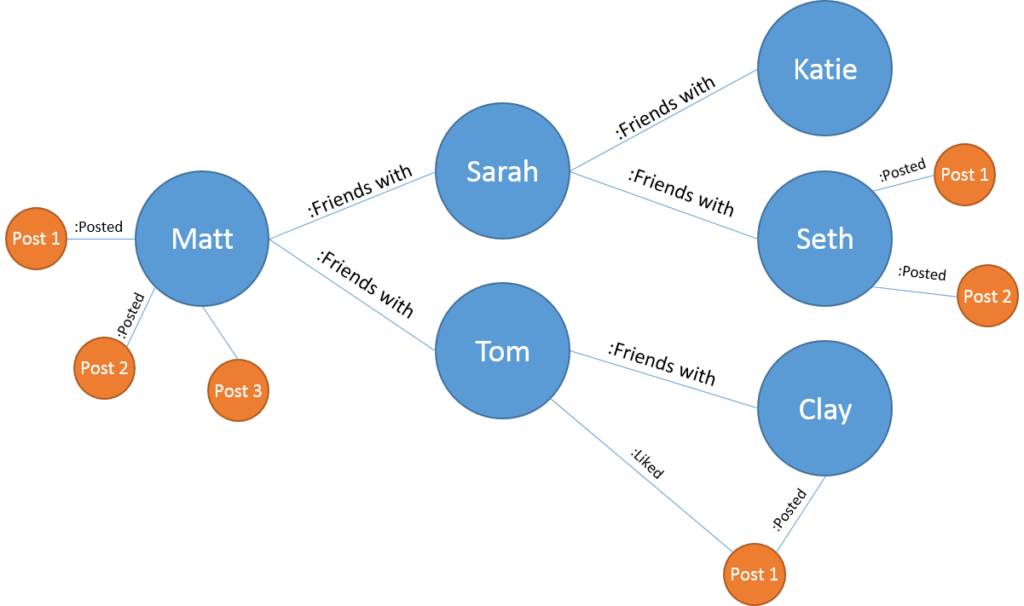
Quando eu preciso de um Neo4J?
Quando seus relacionamentos possuem características próprias e você terá de fazer consultas complexas baseadas nessas características e ordená-las pela proximidade de um registro do outro no mapa de relacionamentos (grafo) deles. Mais resumidamente: você desenha seu problema como um grafo? Pode ser uma boa considerar o Neo4J.
Quando eu não devo usar um Neo4J?
Você vê clara e facilmente o seu problema modelado em tabelas (ou outra estrutura de dados)? Então não use ele, use o modelo mais apropriado como ER ou document-based.
Não vejo nenhum concorrente especificamente orientado a grafos para falar junto do Neo4J, embora existam alguns multi-modelos com suporte à grafos bem proeminentes, que falarei mais tarde.
5 Time-series
Estes bancos são muito específicos para o problema de retornar séries de dados baseados em intervalos de tempo. Mas não estou falando de qualquer série de dados, mas um volume muito grande, como dados estatísticos e métricas analíticas que são capturadas e consultadas a todo instante. E quando falo a todo instante, quero dizer tempo-real.
O mais proeminente neste segmento, chamado de TSBD (time-series databases) é o InfluxDB. Curiosamente a sua sintaxe é muito semelhante ao SQL tradicional, especialmente as consultas.
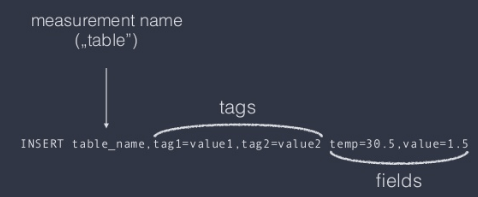
Quando eu preciso de um InfluxDB?
Quando seus dados são associados a um período específico de tempo, são coletados dessa forma e precisam ser analisados dessa forma. Ações da bolsa, análise de tráfego web, estatísticas de consumo de recursos, esse tipo de problema de dados vs tempo.
Quando eu não preciso de um InfluxDB?
Nos demais cenários que não o bem específico acima.
Existem poucos mecanismos time-series, e nenhum tem alcançado tanta popularidade quanto o InfluxDB, por isso que não mencionarei nenhum nesta seção.
6 Multi-modelo
E se pudéssemos juntar o melhor dos dois mundos? Unir modelos relacionais e não-relacionais em um mesmo banco? Seria a solução perfeita, certo?
Essa é a proposta dos bancos multi-modelo. Nunca usei nenhum, para falar a verdade, e confesso que sou bem cético, afinal, quem quer fazer tudo não se torna realmente bom em nada, não é mesmo? Pelo menos é nisso que eu acredito e até que eu conheça algum case que realmente me impressione, continuarei achando isso.
No entanto, é fato que os bancos multi-modelo estão cada vez mais poderosos e famosos. Desde add-ons de implementações tradicionais como MySQL + Memcached ou Oracle 12c + Oracle NOSQL até bancos NOSQL inovadores como o OrientDB (documento + grafos), ArangoDB (document, grafo e chave-valor) e CouchBase (relacional + document + chave-valor).
Quando eu preciso de um banco multi-modelo?
Não sei informar razões comprovadas, mas posso supor que seja quando você quer juntar o melhor de diversas abordagens em um banco só.
Quando eu não devo usar um banco multi-modelo?
Quando apenas um modelo já supre as suas necessidades, ou quando a combinação de bancos mono-modelo diferentes produzirão um melhor resultado final (a tese que eu acredito).

Persistência poliglota na programação
“Ok, tudo isso é muito bonito, falar de usar a ferramenta certa para cada tarefa e tudo mais, super apoio, mas e como é que você programa com tantas fontes de dados diferentes?”
Essa é uma pergunta muito frequente. Quando falo em sala de aula que na empresa em que trabalho durante o dia usamos uma meia-dúzia de mecanismos de persistência diferentes, que aplico persistência poliglota no dia-a-dia, os alunos ficam meio confusos. E isso é normal.
Aprendemos na cadeira de banco de dados como modelar todo o domínio do nosso problema em um único banco de dados. Jamais somos ensinados como distribuir os dados (e depois consultar) usando bancos diferentes, quiçá mecanismos de persistência completamente diferentes!
Existem diversas abordagens possíveis e todas elas exigirão de você um conhecimento intermediário para avançado em arquitetura de software. Não dá pra fazer apenas com o que vemos na faculdade, infelizmente. Conforme aumenta o número de mecanismo que você precisar “plugar” na sua aplicação, mas conhecimento avançado você irá precisar.
Entenda que o primeiro e mais importante conceito é a separação de camadas. Você irá precisar isolar completamente sua camada de dados e abstrair completamente os diversos mecanismos sob uma única biblioteca de classes de entidades, para que as camadas superiores à de dados não tenham de lidar com complexidade alguma de dados. Agora, na camada de dados, aí que irão morar todos os seus problemas com persistência poliglota…
Facilmente eu poderia escrever um artigo inteiro apenas sobre implementação de persistência poliglota, mas como esse já passou das 3 mil palavras, vou deixar isto para uma próxima oportunidade. Por ora, estude as seguintes abordagens que vão te ajudar a entender como pode trabalhar com o problema:
- DAO + Gateway Pattern + Factory Method + Abstract Factory
- Repository Pattern + Dependency Injection + Inversion of Control
- ESB + SOA
- Micro serviços
E muita informação pode ser encontrada no livro Padrões de Arquitetura de Aplicações Corporativas, de Martin Fowler, que já citei nesse post dos livros mais recomendados de programação.
Casos de Uso
Os casos de uso mais notórios e frequentes de persistência poliglota são dos gigantes do e-commerce. Ok, provavelmente as redes sociais são casos de uso ainda mais incríveis, mas como temos muito mais e-commerces de grande porte do que redes sociais, vou falar delas aqui.
Soube através de fontes confiáveis que os e-commerces do grupo B2W, o maior grupo do Brasil neste segmento, com sites como Shoptime, Submarino e Americanas.com usam persistência poliglota em sua arquitetura. Eles usam:
- entidade-relacional: dados dos clientes, informações de pagamento, transações, etc, toda a parte mais crítica e sensível dos dados, até por uma questão legal para poderem ter certificados de segurança e confiabilidade e poderem oferecer bandeiras como VISA e Master aos clientes.
- document-based: catálogo de produtos. Como cada categoria de produto possuem características completamente diferentes das outras categorias (tente montar uma tabela ER onde você possa salvar vestuário e eletrônicos juntos…), o modelo de documentos JSON schemaless é perfeito pra isso. Também é muito comum usarem mecanismos focados em busca como Elasticsearch para que a pesquisa do site seja rápida e eficiente.
- key-value: carrinho de compras. Até que o cliente da compra seja identificado e a compra finalizada, essa informação não precisa estar no banco de dados, pois é temporária. Sendo assim, manter esses dados em memória é uma opção muito mais rápida do que ir no disco cada vez que o cliente indeciso mudar de opinião.
- grafo: produtos relacionados, recomendações, upsell, cross-sell, etc. Cada produto se relaciona a outros produtos de diversas maneiras: seja por características semelhantes, seja porque são complementares, seja porque são comprados frequentemente em conjunto, etc. Guardar e consultar todas essas variáveis é dificílimo em um ER e importantíssimo para aumentar o ticket de venda, fidelizar clientes, maximizar o ROI, etc.
Faz mais sentido pra você agora?
Um outro caso de uso que posso falar com mais propriedade é de duas startups em que tive a oportunidade de trabalhar mais diretamente com persistência poliglota: o Route e a Umbler.
No Route usávamos (a startup está em vias de fechar, já não trabalho mais lá) MongoDB para armazenamento-base, uma vez que o volume de dados que armazenávamos era absurdamente alto e sem esquema definido. O Mongo nos permitia escalonamento vertical e horizontal facilmente, bem como documentos JSON fáceis de trabalhar via APIs REST. Para apoiar o Mongo, que no nosso caso foi otimizado para escrita, usávamos ainda:
- Elasticsearch para as pesquisas internas da aplicação;
- Redis para cache de consultas comuns de dados de interface do usuário, evitando ter de ir no MongoDB a cada requisição e
- RabbitMQ, um mecanismo de fila de tarefas in-memory que garante que todas requisições sejam atendidas de maneira assíncrona, sem bloquear a aplicação principal.
Já na Umbler, startup em que estou atualmente, temos um caso ainda mais complicado pois nossa base de dados principal é SQL Server, onde mantemos o core da aplicação, herança de uso dessa tecnologia por parte dos fundadores da empresa. Aliado ao SQL Server temos:
- Redis para os dados do gráfico de consumo de RAM e CPU que exibimos aos nosso clientes em tempo real;
- InfluxDB para o monitoramento de estado dos servidores e notificações de consumo dos clientes que estão excedendo seus recursos contratados (para que possam fazer upgrade);
- Elasticsearch para a infraestrutura que controla os logs de envio de emails dos nossos clientes, visando controlar o spam (usando um stack chamado ELK) e, para finalizar e
- usamos RabbitMQ aqui também, para a mesma finalidade que tinha no Route.
Simples, não?! XD
Conclusão
Acho que consegui passar um pouco do sei sobre esse fantástico assunto que são os mecanismos de persistência variados que possuímos no mercado hoje. Ao contrário de muitos que acham que é ruim termos tantas opções, uma vez que dificulta o estudo, acho o contrário. É ótimo ter tantas opções de ferramentas, afinal, não podemos ser mestres no martelo se os projetos atuais precisam de furadeiras, certo? 🙂
Até a próxima!










Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.