
Uma pergunta muito frequente que recebo é como modelar corretamente bases MongoDB. A resposta mais honesta é que depende.
Sua aplicação faz mais leitura que escritas? Que dados precisam estar agrupados quando é feito uma leitura? Quais são as preocupações com performance que devemos ter na sua aplicação? O quão grande serão os documentos? O quão grande será a base como um todo?
Todas essas perguntas, e muitas outras, definem como devemos projetar nossos schemas em MongoDB. Sim, MongoDB é schemaless, mas ainda assim, a maior parte dos problemas de performance (e frustrações dos desenvolvedores) que usam MongoDB advém de schemas ruins. Então, sim, você deve pensar sobre seu schema e essa série sobre os padrões mais comuns para schema MongoDB é justamente pra te ajudar com isso.
Nesta terceira e última parte da minha série sobre padrões para modelagem de dados para MongoDB, nós vamos estudar os últimos 4 padrões mais comuns de serem aplicados nas empresas que usam este banco. Para você que está chegando agora, os outros artigos desta série são:
E os padrões que já vimos até agora foram:
- Approximation: para maior performance em escrita de estatísticas mas com menos precisão, adicionando uma camada de controle na aplicação;
- Attribute: para maior performance em buscas de campos similares que estão sofrendo com múltiplos índices, tornando-os um atributo array;
- Bucket: para reduzir o tamanho da base que cresce rapidamente com registros em real time, agregando-os em documentos;
- Computed: para aumentar a performance de consulta de agregações de dados que podem ser pré-computados;
- Document Versioning: para manter histórico de todas versões de um documento, sem prejudicar a performance de consulta;
- Extended Reference: para diminuir os JOINs entre coleções mantendo cópias de dados essenciais e que não mudam com frequência nos documentos principais;
- Outlier: para tratar exceções em documentos sem ferir o seu schema que atende a maioria da coleção e sem agredir a performance;
- Pre-allocation: para ganho de tempo de escrita (em versões anteriores a MongoDB 3.2), pré-alocando o espaço para documentos com tamanho de campos previsível;
E na imagem abaixo você consegue ver a lista completa de padrões apresentados nesta série mais uma vez.
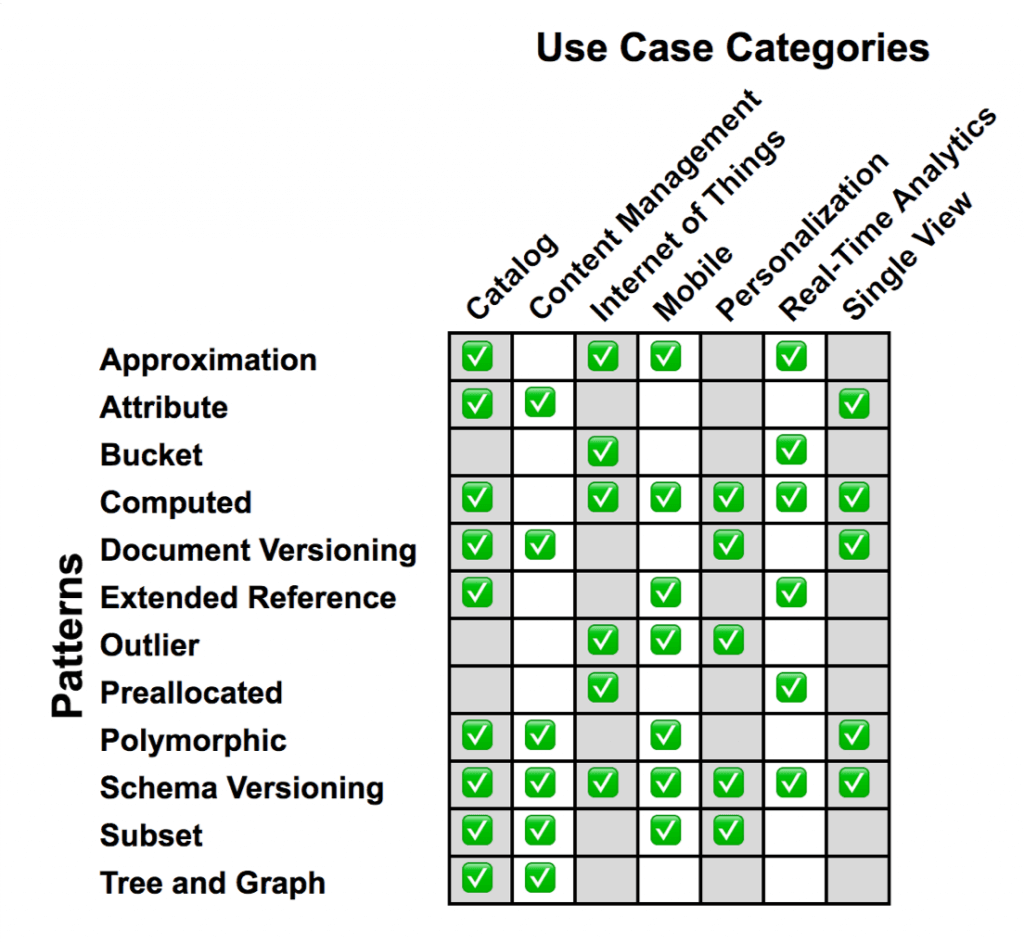
No artigo de hoje então, veremos os 4 do final da lista, que está em ordem alfabética, não tem nada a ver com popularidade do padrão ou importância.

Polymorphic
Este padrão, Polimórfico, é útil quando você tem uma variedade de documentos muito similares entre si (mas não idênticos) e precisam ser mantidos na mesma coleção pois isso facilita as consultas a essas informações e tem mais performance do que fazer JOINs. Ex: coleção de atletas de diferentes esportes, base de veículos de diferentes tipos, classificados online de diversos produtos, etc.
Vamos pegar este exemplo de coleção de atletas de diferentes esportes. Em um banco relacional, teríamos uma tabela-mãe contendo os campos em comum entre todos atletas e depois as tabelas-filhas, especializadas para cada esporte, com uma chave estrangeira para a tabela-mãe.
No entanto, em MongoDB, usando o padrão polimórfico, teríamos documentos com uma base semelhante e características exclusivas, ao mesmo tempo, como abaixo.
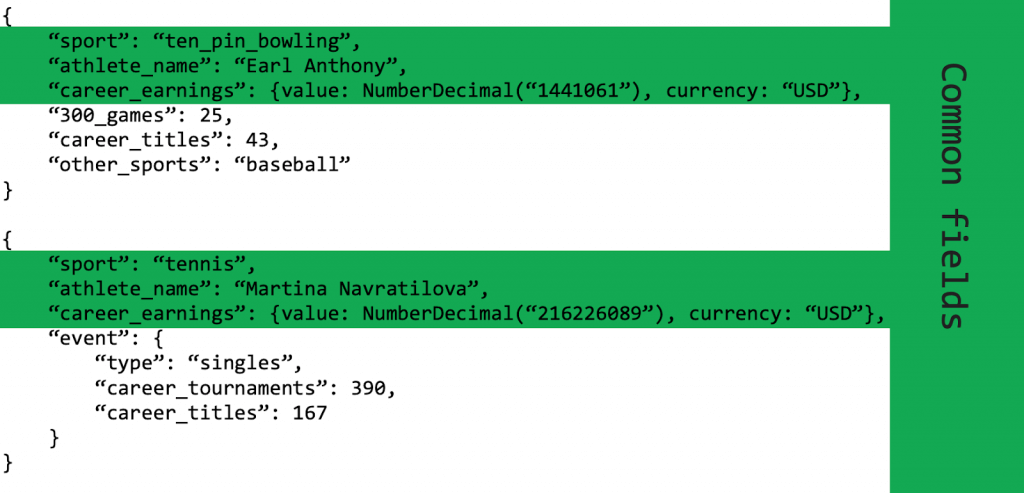
Assim, quando você desejar fazer consultas de todos atletas, consegue de maneira simples e performática. Se desejar fazer consultas de atletas de um esporte específico, considerando filtros específicos desse esporte, também consegue, de maneira simples e performática também.
Uma coisa interessante é que esse padrão aqui também funciona bem em sub-documentos, como abaixo, onde em alguns eventos são solo e outros em duplas, no tênis.
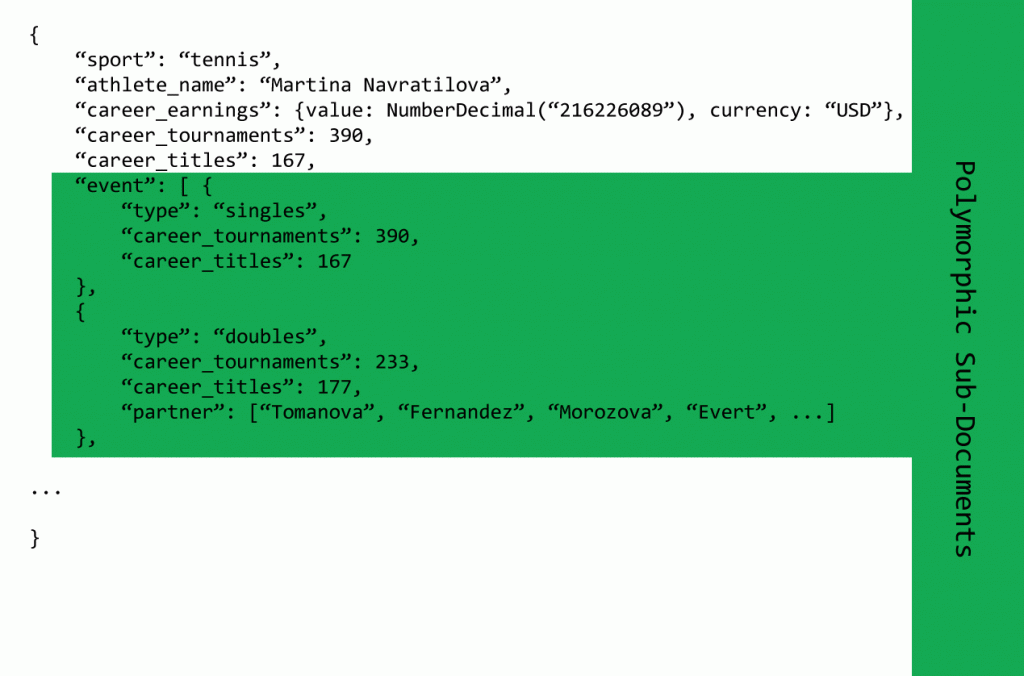
Na sua aplicação, obviamente, será necessário ter essa resiliência para os dados que virão do banco, até mesmo usando o polimorfismo presente em algumas linguagens de programação como Java e C#. Talvez possamos considerar isso como a “desvantagem” desse padrão, pois exige lógica adicional na aplicação.
Este é, de longe, o padrão mais usado em MongoDB, o que eu chamava simplesmente de “VIEW” antes de conhecer o nome certo, pois me lembrava as VIEWS dos bancos relacionais que justamente faziam esse papel de agregar em uma tabela só os dados de diferentes tabelas. Curiosamente, o caso de uso mais comum deste padrão é em aplicações Single View.
Mais informações em Polymorphic.
Schema Versioning
Este padrão, Versionamento de Schema, é útil quando o seu schema mudou ao longo da existência da sua base de dados e documentos com diferentes versões de schema precisam coexistir na mesma coleção. Em uma base relacional, mudar o schema é um processo relativamente delicado pois envolve uma análise profunda do schema atual vs novo, migração de dados e downtime da aplicação.
No MongoDB, é um processo igualmente importante, mas bem menos dolorido e sem downtime. Basicamente, se temos o documento abaixo, com uma pessoa e seus contatos telefônicos…
|
1 2 3 4 5 6 7 8 |
{ "_id": "<ObjectId>", "name": "Anakin Skywalker", "home": "503-555-0000", "work": "503-555-0010" } |
…e mais tarde decidimos adicionar um campo para celular, é bem simples, certo? Basta adicionar mais um campo…
|
1 2 3 4 5 6 7 8 9 |
{ "_id": "<ObjectId>", "name": "Darth Vader", "home": "503-555-0100", "work": "503-555-0110", "mobile": "503-555-0120" } |
Mas e se mais tarde entendemos que um telefone residencial (home) não é mais algo onipresente e ao mesmo tempo surgiram outras formas de comunicação ainda mais importantes, como as redes sociais.
Prevendo novas alterações, podemos repensar esta estrutura para um array de contatos, usando o padrão Attribute (que falei no primeiro post da série), muito mais flexível e igualmente poderoso. Neste caso, temos um grande ponto de ruptura e aqui vale a pena versionar o schema, colocando um campo para isso:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "_id": "<ObjectId>", "schema_version": "2", "name": "Anakin Skywalker (Retired)", "contact_method": [ { "work": "503-555-0210" }, { "mobile": "503-555-0220" }, { "twitter": "@anakinskywalker" }, { "skype": "AlwaysWithYou" } ] } |
Ambas versões de schema podem coexistir tranquilamente e caberá adaptar na sua aplicação para verificar esse campo para conseguir utilizar os documentos corretamente. Essa seria a primeira desvantagem deste padrão.
A segunda desvantagem é que com o passar do tempo, você pode ter de criar um script de migração de schema, em lote no MongoDB, se começar a ter tantas versões de schema que adicione muita complexidade na sua aplicação. Eu mesmo não recomendaria conviver com mais do que 2 schemas e ainda assim, recomendo que a sua própria aplicação, conforme os cadastros forem sendo atualizados, eles já serem salvos no schema mais recente.
Mais informações em Schema Versioning.

Subset
Este padrão, Subconjunto, é útil quando a quantidade de memória RAM não está sendo o suficiente para o working set (os dados que são mais acessados, o Mongo mantém na memória) pois existem documentos grandes e, ao mesmo tempo, um subconjunto grande desses dados não são usados com frequência pela aplicação.
Como exemplo podemos citar documentos que possuem arrays de subdocumentos no seu interior. Muitas vezes não há a necessidade de se retornar todos estes elementos em uma consulta. Pense em um produto de um ecommerce com mil avaliações. Você vai listar todas elas na tela? Quando você faz uma consulta por um produto, necessariamente precisa-se retornar todas elas junto do documento?

Muito provavelmente que somente as 10 avaliações mais recentes façam sentido de serem exibidas logo de cara. Assim, ao invés de armazenar TODAS as reviews do produto junto do mesmo, podemos armazenar somente um subconjunto, como as 10 mais recentes, e as demais ficam em uma coleção específica de avaliações, como abaixo.

Este é apenas um exemplo, o mindset é de que no caso de documentos grandes que estejam onerando o working set, somente os dados mais acessados deveriam estar no documento principal e os demais em subdocumentos.
A desvantagem aqui é a gestão deste subconjunto. Afinal, neste exemplo, se você quer ter sempre as 10 reviews mais recentes do produto, toda vez que uma nova review for postada, você terá de adicioná-la no subconjunto e na coleção de reviews, além de remover a mais antiga do subconjunto, certo? E esta é uma regra simples, então tome cuidado com a gestão dos seus subconjuntos!
Mais informações em Subset.
Tree
Este padrão, Árvore, é útil quando você precisa armazenar dados hierárquicos no seu documento. Ex: gestores e subordinados de um funcionário, categorias e subcategorias de um produto, etc.
Enquanto que em um banco relacional isso geralmente é resolvido com diversos registros com chaves primárias e estrangeiras pra todo lado, em MongoDB a resolução é muito mais direta, embora envolva duplicação de dados.
Pegando o exemplo de categorias e subcategorias de um produto, o padrão Árvore define que o seu documento de produto deve ter um campo array para as categorias-pai (ancestor_categories, em ordem), além de um campo para a categoria imediatamente superior (parent_category), como abaixo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ _id: <ObjectId>, name: "Samsung 860 EVO 1 TB", part_no: "MZ-76E1T0B", price: { value: NumberDecimal("169.99"), currency: "USD" }, parent_category: "Solid State Drives", ancestor_categories: [ "Solid State Drives", "Hard Drives", "Storage", "Computers", "Electronics" ] } |
Note que aqui usei apenas os nomes das categorias, mas que poderíamos ter subdocumentos com chave-valor, caso seja necessário. Note também, que ter um campo parent_category diretamente na raiz do documento permite usar os recursos de atravessamento em grafo do MongoDB.
No caso do use case de funcionários, bastaria ter um outro campo array para os subordinados dele, ao invés de apenas os seus gestores.
A vantagem deste padrão é a velocidade de carregar a árvore hierárquica deste documento e como desvantagem temos a duplicação de dados e a complexidade de atualização dos mesmos. Logo, é importante que ele seja aplicado em dados que mudem com muita frequência, embora a hierarquia em si possa mudar bastante, basicamente o mesmo risco do padrão Extended Reference, já citado anteriormente.
Mais informações em Tree.
E com isso encerro esta série de padrões de modelagem de dados em MongoDB. Espero que seja de utilidade prática para as suas aplicações e que tenha conseguido lhe mostrar um pouco mais da versatilidade e poder da orientação à documentos deste fantástico banco de dados.
Um abraço e até a próxima!










Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.