
Uma das coisas mais difíceis para quem está entrando agora neste mundo de bancos não-relacionais é modelagem de dados. E quando o assunto é MongoDB, o banco não relacional mais famoso do mercado segundo diversas pesquisas, não é diferente.
Muitos desenvolvedores começando com esta tecnologia “apanham” muito para se desvencilhar do paradigma relacional e abraçar a orientação à documentos, modelo do MongoDB. Muitos são os fatores para essa dificuldades, mas posso citar alguns que entendo que são os mais fortes: ausência de ensino formal nas instituições de ensino, baixa maturidade do modelo frente ao concorrente (o modelo relacional está no mercado há décadas) e adoção errada da tecnologia não relacional, sendo que este último eu já falei anteriormente aqui no blog.
O fato é, o uso e a modelagem de dados não relacionais varia muito mais do que no paradigma relacional e você não vai encontrar no mercado nada parecido com as 4 Formas Normais. Mas, se dermos um zoom em apenas uma das tecnologias, conseguimos colocar um pouco mais de luz neste desafio que é a modelagem de dados, neste caso, no MongoDB.
E este é o objetivo do artigo de hoje.

Construindo com Padrões
Assim como na engenharia de software nós temos os Padrões de Projeto (Design Patterns no original), o time do MongoDB resolveu compilar o conhecimento acumulado da última década de uso deste banco não relacional em alguns padrões de modelagem comuns e reutilizáveis, em uma excelente série de posts em seu blog, intitulada Building With Patterns.
Minha ideia é trazer em uma série de posts aqui no blog, os padrões descritos pelo time do MongoDB, mas não apenas traduzindo-os, mas tentando trazer de uma maneira mais didática cada um dos padrões. Começando pela matriz abaixo, achei ela sensacional. Ela é apenas uma linha guia, mas que facilita bastante para consultas rápidas. No eixo horizontal, os padrões de modelagem encontrados pelo time do MongoDB, e no vertical, os casos de uso mais comuns destes padrões.
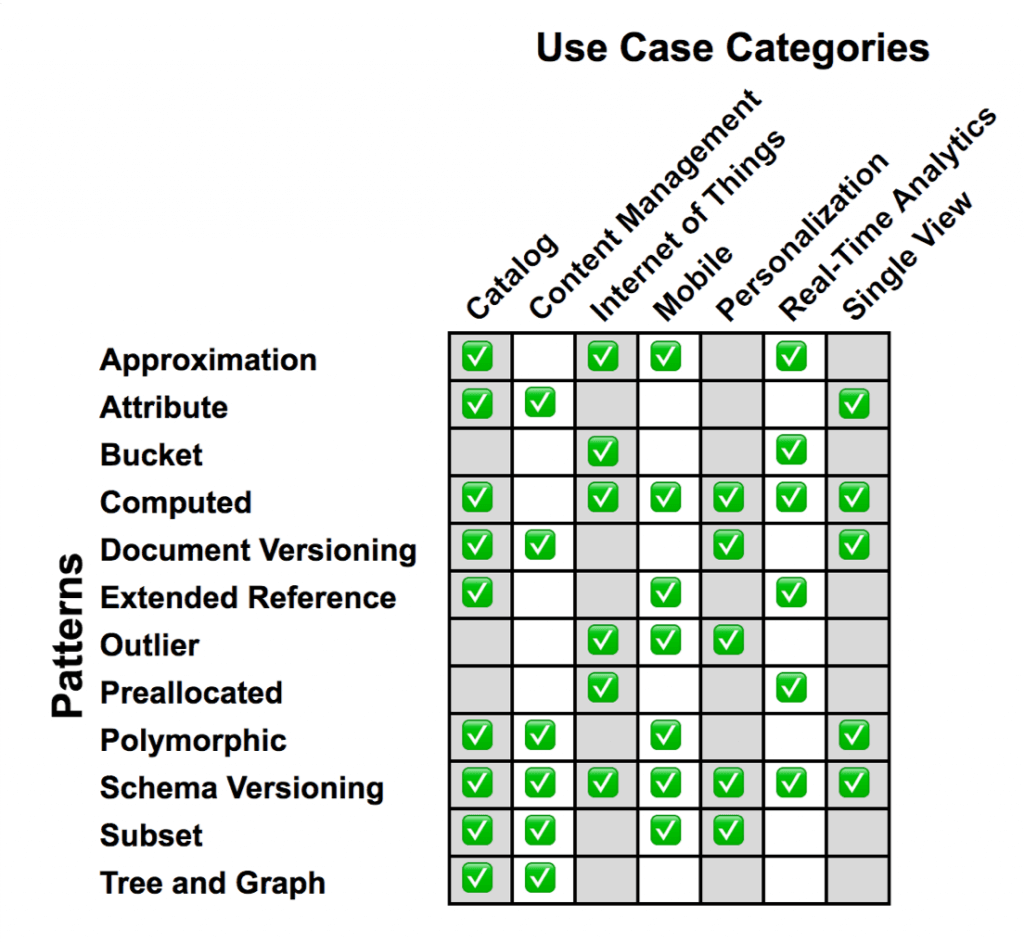
Note que analisando os use cases listados pelo time do MongoDB, também podemos presumir onde eles entendem que ele melhor se adequa, o que corrobora com a minha máxima de alguns anos que MongoDB não substitui os bancos relacionais em todos cenários, mas sim em alguns cenários específicos, que, segundo o time do MongoDB, são:
- Catalog: como catálogo de produtos e serviços;
- Content Management: como em ECMs (gerenciadores de conteúdo corporativo);
- Internet of Things: como em sistemas com sensores real-time, como na indústria 4.0;
- Mobile: como em aplicações móveis de baixa latência e alta escala;
- Personalization: como em sistemas com schema de dados personalizável para entregar conteúdo relevante aos usuários, muito usados no marketing digital;
- Real-Time Analytics: como em sistemas de estatísticas real-time;
- Single View: como em sistemas de dashboards, gerenciais e outros que agregam informações de diferentes fontes em uma base só;
Nesta série, vou passar rapidamente pela teoria de cada um dos padrões, explicando-os em alto nível, sua aplicação e linkando ao artigo original (em inglês) que o detalha mais profundamente. Se algum deles não ficar bem explicado, conto com o seu feedback nos comentários que procurarei trazer mais luz ao assunto.
Antes desse conteúdo mais denso, sugiro assistir ao vídeo abaixo. Falo da forma mais comum de modelar dados com MongoDB e talvez seja o que você está precisando.

Approximation
Este padrão, Aproximação, é útil quando temos que manter registro de estatísticas em grande volume na aplicação, estamos sofrendo com a quantidade de escritas e não precisamos que estas estatísticas sejam exatas, podem ser aproximadas. Ex: população de países, pageviews de um grande portal, número de resultados de pesquisa de um grande buscador, etc.
Para fazer isto, a aplicação deve armazenar as estatísticas recentemente recebidas em um cache por exemplo e somente escrever no banco de dados quando atingir um limiar aceitável (por ex, 100). Usando este limiar hipotético de 100:1, conseguimos reduzir drasticamente (em 99 vezes, neste caso) as escritas no MongoDB, liberando sua performance para operações mais importantes.
A desvantagem deste padrão é que as estatísticas não serão exatas e eventualmente pode haver pequena perda de dados caso ocorra falha no cache. Por isso é importante que seja usado somente em casos que possamos ter estatísticas aproximadas.
Mais informações em Approximation.
Attribute
Este padrão, Atributo, é útil quando temos diversos campos em um documento que são usados em filtros de consulta e estamos sofrendo com a quantidade de índices necessários para que as consultas performem com velocidade. Ex: as diferentes datas de lançamento de um filme internacional, as diferentes unidades de medida de um produto internacional, as diferentes traduções de um texto, etc.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ title: "Star Wars", director: "George Lucas", ... release_US: ISODate("1977-05-20T01:00:00+01:00"), release_France: ISODate("1977-10-19T01:00:00+01:00"), release_Italy: ISODate("1977-10-20T01:00:00+01:00"), release_UK: ISODate("1977-12-27T01:00:00+01:00"), ... } |
Se um conjunto destes campos possuem características em comum, como o mesmo tipo, podemos agrupá-los em um atributo do tipo array, criando apenas um índice nele. Por exemplo, em uma base de filmes de cinema, ao invés de termos atributos de lançamento para cada país, criamos um atributo “lancamentos” como um array de subdocumentos estilo chave-valor, onde a chave seria o país e o valor seria a data de lançamento naquele país.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ title: "Star Wars", director: "George Lucas", … releases: [ { location: "USA", date: ISODate("1977-05-20T01:00:00+01:00") }, { location: "France", date: ISODate("1977-10-19T01:00:00+01:00") }, { location: "Italy", date: ISODate("1977-10-20T01:00:00+01:00") }, { location: "UK", date: ISODate("1977-12-27T01:00:00+01:00") }, … ], … } |
A contra-indicação deste padrão é se você não aplicá-lo no conjunto de atributos correto, que façam sentido serem agrupados em um atributo só.
Mais informações em Attribute.
Bucket
Este padrão, Balde, é útil quando temos um alto fluxo de dados de dados em tempo real e estamos sofrendo com a escrita elevada e o o crescimento rápido da base, o que acaba afetando as consultas. Ex: sensores que enviam dados em real time, monitoramento de recursos de servidores, etc.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ sensor_id: 12345, timestamp: ISODate("2019-01-31T10:00:00.000Z"), temperature: 40 } { sensor_id: 12345, timestamp: ISODate("2019-01-31T10:01:00.000Z"), temperature: 40 } { sensor_id: 12345, timestamp: ISODate("2019-01-31T10:02:00.000Z"), temperature: 41 } |
Ao invés de escrever cada registro em um documento separado, criamos “baldes” de registros baseados em timestamp. Ou seja, se você recebe um registro por segundo, ao invés de termos 60 documentos por minuto, podemos ter um documento por minuto compreendendo o timestamp dos últimos 60 segundos.
Essa abordagem não reduz tanto a escrita quanto o padrão Approximation, pois estaremos escrevendo na mesma quantidade (mas não no mesmo volume de dados), mas mantém a fidelidade das estatísticas no detalhe.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
{ sensor_id: 12345, start_date: ISODate("2019-01-31T10:00:00.000Z"), end_date: ISODate("2019-01-31T10:59:59.000Z"), measurements: [ { timestamp: ISODate("2019-01-31T10:00:00.000Z"), temperature: 40 }, { timestamp: ISODate("2019-01-31T10:01:00.000Z"), temperature: 40 }, … { timestamp: ISODate("2019-01-31T10:42:00.000Z"), temperature: 42 } ], transaction_count: 42, sum_temperature: 2413 } |
A desvantagem é apenas a lógica de escrita que fica um pouco mais complexa, pois ao invés de simplesmente sair salvando novos documentos, você tem de guardar a estatística no “balde” certo.
Mais informações em Bucket.
Computed
Este padrão, Computado, é útil quando temos a necessidade e ter dados agregados em bases com grande volume, fazendo com que a performance de agregações não seja boa. Ex: soma de vendas por produto, visitantes de um grande portal por país, ocorrência de palavras em volumes de texto ou no exemplo abaixo, ingressos de cinema vendidos e receita por filme.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "ts": DateTime(xxx), "theather": "Overland Park Cinema", "location": "Boise, ID", "movie_title": "Jack Ryan: Shadow Recruit", "num_viewers": 760, "revenue": 7600 } { "ts": DateTime(xxx), "theather": "City Cinema", "location": "New York, NY", "movie_title": "Jack Ryan: Shadow Recruit", "num_viewers": 1496, "revenue": 22440 } { "ts": DateTime(xxx), "theather": "Alger Cinema", "location": "Lakeville, OR", "movie_title": "Jack Ryan: Shadow Recruit", "num_viewers": 344, "revenue": 3440 } |
Para resolver este problema, deixamos os dados pré-computados para consulta posterior, com duas alternativas diferentes.
Alternativa 1, se a escrita não é frequente, podemos ter campos computados no documento principal que, a cada atualização, são recalculados. Por exemplo, um campo num_viewers em um documento de filme de cinema que é incrementado a cada nova venda de ingresso daquele filme.
Alternativa 2, se a escrita é frequente, a aplicação pode controlar um intervalo de tempo em que ela vai realizar as agregações e deixar salvo, provavelmente em uma base específica para armazenar estas computações que serão analisadas mais tarde.
|
1 2 3 4 5 6 7 8 |
{ "ts": DateTime(xxx), "movie_title": "Jack Ryan: Shadow Recruit", "num_viewers": 2600, "revenue": 33480 } |
Este é um padrão que adiciona relativa complexidade na aplicação, então não deve ser usado exceto quando realmente necessário.
Mais informações em Computed.
Para acompanhar os demais padrões, leia a parte 2 desta série.
* Espero que este artigo tenha sido útil para você que está aprendendo MongoDB. Para conteúdo mais aprofundado, recomendo meus livros. Para videoaulas, recomendo o meu curso online (abaixo).










Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.