

Foi em 2016 que passei a ouvir falar de micro serviços (microservices) mas faz poucos meses que passei a me interessar realmente pelo tema, uma vez que comecei a estudar Node.js para uso em meus projetos.
Micro serviços é uma maneira particular de desenvolver aplicações de maneira que cada módulo do software é um serviço standalone cujo deploy e escala acontecem de maneira independentes da “aplicação principal” (não confundir com SOA). Enquanto na arquitetura tradicional de software, chamada monolítica, quebramos uma grande aplicação em bibliotecas, cujos objetos são utilizados in-process, em uma aplicação modular como proposta na arquitetura de microservices cada módulo recebe requisições, as processa e devolve ao seu requerente o resultado, geralmente via HTTP.
A ideia não é exatamente nova, é usada em ambientes Unix desde a década de 60, mas recentemente se tornou o epicentro de uma grande revolução na forma como as empresas estão desenvolvendo software ágil baseado em equipes enxutas responsáveis por componentes auto-suficientes.
Neste post irei abordar os conceitos, detalhes, vantagens, desvantagens e principais dúvidas dessa arquitetura, bem como porque ela está sendo tão utilizada atualmente e como começar a organizar suas aplicações orientadas dessa maneira.
Veremos neste artigo:
- A motivação por trás dos micro serviços
- Vantagens e desvantagens de microservices
- O que você deve ter em mente
- O quão grande é/deve ser um micro serviço?
- Como começar com micro serviços?
Vamos lá!
Antes de continuar, caso tenha interesse em aprender a construir microservices na prática com Node.js, confira o meu curso.

A motivação por trás dos micro serviços
Muitas são as buzzwords do mundo de desenvolvimento de software e esta me pareceu mais uma quando a ouvi pela primeira vez. Apesar do seu nome ser auto-explicativo, é interessante estudarmos os reais impactos que uma arquitetura composta por diferentes módulos conversando via um canal lightweight como HTTP pode causar na forma como programamos e nos resultados que obtemos com software.
Resumidamente, o estilo de arquitetura em microservices é uma abordagem de desenvolver uma única aplicação como uma suíte de pequenos serviços, cada um rodando o seu próprio processo e se comunicando através de protocolos leves, geralmente com APIs HTTP. Estes serviços são construídos em torno de necessidades de negócio e são implantados de maneira independente geralmente através de deploy automatizado (pelo menos em um cenário ideal deveria ser assim). Existe um gerenciamento centralizado mínimo destes serviços e cada um deles pode ser escrito em uma linguagem diferente e utilizando persistências de dados diferentes também.
Para entender melhor a motivação por trás de microservices vale relembrar como os projetos são programados hoje, geralmente em três grandes partes: um client-side com a interface do usuário, uma base de dados com as informações do sistema, e uma camada server-side com a lógica da aplicação. A camada server-side lida com as requisições do usuário, executa a lógica de negócio, retornar e atualiza dados da base e disponibiliza informações prontas para o client-side exibir. Isto é um monólito ou aplicação monolítica, uma vez que gera uma única e grande aplicação com tudo junto. Qualquer mudança no sistema envolve em compilar tudo novamente e implantar uma nova versão do server-side inteiro no servidor.
Toda a aplicação roda em um único processo, usando uma única linguagem server-side e geralmente uma única tecnologia de persistência de dados. Para escalar esse tipo de aplicação você pode adicionar mais recursos no mesmo servidor (escala vertical) ou fazer cópias desse servidor e colocá-las atrás de um load balancer (escala horizontal).
Aplicações monolíticas não são ruins e podem ser muitíssimo bem sucedidas. No entanto, cada vez mais equipes estão frustradas com suas limitações, principalmente quando estão implantando projetos na nuvem. Nestes cenários, os ciclos de mudanças, geralmente rápidos e pontuais como os propostos no Lean Startup, acabam afetando toda a aplicação pois o deploy é monolítico, assim como a aplicação. A escala horizontal requer um custo alto, pois sempre deve ser duplicada a aplicação inteira, e não apenas a parte que necessita de mais desempenho.

Vale lembrar também que aplicações monolíticas exigem que todo o codebase server-side seja escrito na mesma linguagem de programação, o que impede que você tire o máximo proveito de cada cenário usando a ferramenta mais apropriada à ele. Também impede que cada time desenvolva com a maior velocidade possível uma vez que a base de código é a mesma entre todos times.
Estas frustrações levam à arquitetura microservices de construir aplicações como um conjunto de serviços. Como os serviços são implantados de maneira independente, a escala se dá individualmente, tanto na vertical quanto na horizontal, para os serviços que estão precisando de mais desempenho. Usando protocolos comuns e contratos (interfaces) bem definidos, você consegue usar linguagens de programação diferentes de cada serviço, bem como mecanismos de persistência auxiliares que possam ser necessários para cada um deles, como mecanismos de cache, filas, índices, etc.
Para finalizar esta seção, a imagem abaixo do blog do Martin Fowler ilustra bem a diferença da escala entre as duas arquiteturas: monolítica e de micro serviços:
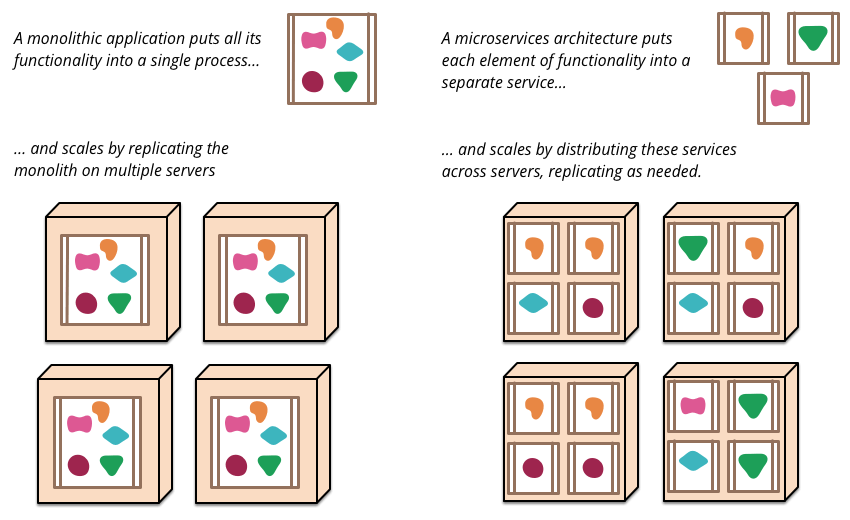
Vantagens e desvantagens de microservices
Não existe uma definição formal de como uma aplicação baseada em micro serviços deve ser construída, mas depois de muito ler a respeito e estudar o assunto notam-se algumas particuliaridades frequentes que podemos denominar como um padrão comum para microservices.
Sempre existiu o desejo dentro da indústria de software de construir programas apenas plugando componentes. Os primeiros esforços neste sentido foram as bibliotecas de funções, mais tarde as bibliotecas de classes e atualmente está em voga os serviços. Note que a componentização sempre existiu, mas o que propõe-se com microservices é que cada componente seja uma aplicação separada e especializada em apenas uma parte da aplicação “completa”. A principal razão por trás dessa escolha, de serviços ao invés de bibliotecas, é que serviços podem ser implantados de maneira separada. Você já tentou atualizar seu software apenas subindo para produção uma DLL ao invés de todas (ou ao menos todas as suas)? É um risco que não vale a pena correr, pois o acoplamento entre as DLLs é muito alto e o ideal é sempre a recompilação do sistema como um todo.
Claro, existe uma desvantagem clara no uso de serviços ao invés de bibliotecas: performance. Bibliotecas rodam no mesmo processo da aplicação, usam memória compartilhada, etc. Serviços dependem de canais de comunicação, como HTTP, para conseguirem tratar e responder as requisições. Exigem também uma coordenação entre os contratos de serviço para que os consumidores consigam “conversar” com os serviço da maneira que eles esperam, bem como receber as respostas que estão preparados.
Esse problema é especialmente preocupante conforme você tenha muitas chamadas síncronas entre seus serviços, pois o tempo de espera total para seu sistema responder será igual à soma de todos os tempos de espera das chamadas síncronas. Neste momento você tem duas opções: mudar para uma abordagem assíncrona ou reduzir o máximo que puder o tempo de espera (e a quantidade) das requisições síncronas. Node.js é uma tecnologia que tenho estudado bastante recentemente e trabalha muito forte com o conceito de chamada assíncronas, muito usado pelo Netflix para não bloquear a experiência do usuário. No entanto, quando isso não é possível, como foi o caso do site do jornal The Guardian, tente limitar o número de chamadas síncronas que você vai precisar, o que no caso deles é a regra de apenas uma chamada síncrona por requisição do usuário.
Apesar desses problemas citados, os benefícios parecem superar os downsides dessa abordagem, pois cada vez mais empresas estão adotando-na.
O que você deve ter em mente
Os serviços irão falhar. Talvez não todos juntos, talvez não rapidamente, mas vaia acontecer. Sendo assim, você deve estar sempre preparado para a falha de um ou mais serviços.
Essa é uma consequência de usar serviços como componentes e sua aplicação deve ser projetada de maneira que possa tolerar a falha de serviços. Qualquer chamado a um serviço pode falhar devido à indisponibilidade de um fornecedor e você tem de saber lidar com isso de maneira amigável com o restante do sistema. Esta talvez seja a maior desvantagem dessa arquitetura se comparada ao jeito monolítico tradicional, uma vez que adiciona uma complexidade adicional significativa. Times que trabalham com micro serviços devem constantemente refletir como a falha de cada serviço afetará a experiência do usuário. No Netflix por exemplo, partes da bateria de testes diária deles inclui derrubar servidores e até datacenters para ver como a aplicação se comporta nestas situações.
Uma aplicação em micro serviços deve ser monitorada em um nível muito superior ao de uma aplicação monolítica tradicional, uma vez que os serviços podem falhar a qualquer momento e se possível, restaurar o funcionamento completo automaticamente. Monitoramento em tempo real deve ser enfático no processo de desenvolvimento, implantação e operação dos serviços. Não que você não tenha de ter esse mesmo cuidado com aplicações monolíticas, mas apenas que com micro serviços isso não é uma opção.
O quão grande é/deve ser um micro serviço?
Uma pergunta bem comum e que cai como uma luva para o próprio nome da “arquitetura’ é: o quão grande deve ser um micro serviço?
Infelizmente o nome micro serviço nos leva a perder tempo demais pensando no que exatamente micro quer dizer. Diversas empresas, de Amazon a Netflix, usam micro serviços de variados tamanhos e não há um consenso sobre eles. Especificamente na Amazon, considerando que cada micro serviço é (e deve) ser tratado como um produto separado e tem seu próprio time (squad, na verdade), eles usam a regra Two Pizza Team: se o time precisa de mais de duas pizzas por refeição para se manter alimentado é porque está grande demais, o que significa não mais de que 12 pessoas. No outro extremo, os menores times recomendados pela Amazon possuem 6 pessoas, o que eu pessoalmente, em minhas experiências como Scrum Master, acredite ser o ideal (você ainda pode chamar meus times de Two Pizza Team considerando que todo mundo gosta de comer vários pedaços de pizza!).
Resumindo, embora não exista uma regra, podemos assumir que se você precisa de uma equipe de mais de 12 pessoas para desenvolver e manter um serviço (considerando tudo: programação, infra, testes, etc), ele está grande demais e você deveria quebrá-lo em serviços menores.
Como começar com micro serviços?
Projetos usando micro serviços geralmente não nascem assim do dia para a noite. O que nota-se na maioria das implementações bem sucedidas é que elas vieram de um design evolucionários, vendo a decomposição em serviços como uma ferramenta que vai aos poucos ajudando a quebrar uma aplicação monolítica que está com problemas de escala, qualidade, etc em diversos componentes menores, como falo em mais detalhes neste artigo.
Neste cenário, o maior desafio é saber como que o monólito irá ser quebrado em serviços. O quê deve ser agrupado em conjunto? O que deve estar separado? Quais bases de dados serão usadas por quais serviços?
Um dos princípios-chave por trás dessas decisões é o de deploy e escala independentes entre os serviços. Se dois serviços sempre tem de ser colocados em produção em conjunto, eles deveriam ser um serviço só. Agora se eu tenho um serviço cujas publicações acontecem sempre por causa de alterações pequenas em um dos seus módulos internos, esse módulo interno deveria ser transformado em um serviço per se.
O site do jornal britânico The Guardian é um bom exemplo de aplicação que foi projetada e construída como um monólito e que vem evoluindo na direção de micro serviços. O monólito ainda é o core do site, mas eles têm adicionado novas funcionalidades usando micro serviços que consomem a API do site principal. Esta abordagem é particularmente interessante pra eles principalmente nos casos de módulos temporários, como um hotsite para cobrir um evento esportivo. Estes hotsites podem ser programados rapidamente na linguagem que for mais conveniente e jogados fora uma vez que não fazem mais sentido.
E aí, motivado para trabalhar com essa abordagem? Vamos trocar experiências nos comentários!
Quer ver isso na prática com Node e Mongo? Dê uma olhada nesta série de artigos e neste outro que falo de boas práticas.
Curtiu o post? Então clica no banner abaixo e dá uma conferida no meu livro sobre microservices com Node.js!










Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.
Bem interessante a ideia de microserviços, apesar da desvantagem da performance. Acredito que a chave para o desenvolvimento é a modularização e essa arquitetura atende bem. Unica coisa que ainda n entendi bem eh como funcionaria uma tela de cadastro, que ao final envia um email e um sms para o cliente. Como funcionaria o codigo dessa tela chamando esses serviços.
Você chamaria uma API que salva os dados do cadastro, uma API que envia o email e outra que envia o SMS. A chave aqui é não fazer uma API só, com todos endpoints nela, mas sim várias APIs menores (especialistas).
Sobre a performance, dependendo do caso é superior, principalmente se você possuía um serviço monolítico antes. Agora se não usava serviços, apenas chamadas in-proc, realmente pode haver uma queda de performance, mas que se paga com o ganho em produtividade e qualidade.
Parabéns, muito bom o post! Minha principal duvida é essa, como quebrar os serviços, pegando um sistema de controle e faturamento de pedidos, o cadastro de cliente seria um serviço ? as funções referentes ao pedido seria outro serviço ? A parte de faturamento seria outro? Essas são questões que me vem a cabeça.
Exatamente. Ao invés de ter uma única API pra bater todas chamadas, você tem várias. A granularidade é você que decide, desde uma API por domínio de negócio (clientes, pedidos, etc) ou até mesmo a nível de funcionalidade (cadastro de cliente, consulta de cliente, etc). Essa granularidade deve estar consonante à maturidade do seu time em relação a DevOps e Continuous Delivery, para fazer sentido. Caso contrário, microservices mais atrapalhariam do que ajudariam.
Gostei bastante do artigo. Estou começando a estudar sobre o assunto e seu artigo foi um bom ponto de início.
Entendi os drawbacks que você citou, porém algo que ainda me deixa confuso é como manter a integridade/confiabilidade dos dados através dos diversos banco de dados dos módulos.
Imagine os módulos A e B, onde cada um possui seu próprio banco de dados. A tabela Ta do banco A é chave estrangeira da tabela Tb do banco B. Neste caso, se removêssemos ou atualizássemos o registro de B, as atualizações deveriam ser necessariamente refletidas no banco do módulo A. Ou existe uma adaptação para trabalhar com só um banco de dados, onde cada módulo seria responsável por algumas tabelas?
Aqui no banco temos algumas abordagens. Uma delas é um banco de cadastro único dos correntistas que possui alguns microsserviços que são usados por outros. Já os dados da conta dele ficam no banco do core banking, que tem seus próprios microsserviços para acesso. Os dados de cartão de crédito ficam em um banco de um fornecedor externo, acessível também por microserviços. Ambos possuem dados em comum que são usados como chave e no nosso caso um BPM orquestra a comunicação entre os diferentes microsserviços.
Esse é só um exemplo prático.
Entendo, legal a solução.
Pelo que eu tinha entendido, quase que completamente todos os módulos possuíam seus próprios bancos. Mas concordo com a possibilidade de adequar o paradigma para sua execução.
Muito bom! =)
Mas em geral cada módulo possui o seu banco, o que se evita ao máximo é cada módulo possuir dados repetidos em relação aos outros módulos. Se preciso mexer em dados cadastrais, vou conversar com o módulo de cadastro, se preciso mexer em dados analíticos, vou conversar com o módulo analítico, e assim por diante. Isso permite que cada módulo tenha a tecnologia de banco mais adequada para sua necessidade e sofra menos com a escala.
Mas sem essa replicação, nem mesmo da chave estrangeira, os JOINs são feitos pela aplicação?
Neste caso, até o tempo de transferência dos dados seria grande, pois iríamos trazer quantidades enormes de dados.
Se você fala do JOIN do SQL, quando se trabalha com persistência poliglota (vide outro artigo aqui do blog) nem mesmo usa-se só bancos SQL, ou seja, não há JOINs. As junções de dados devem ser feitas a nível de aplicação, geralmente usando-se múltiplas chamadas a microsserviços em paralelo para conseguir compor uma interface, por exemplo. A Amazon, uma das grandes precursoras desse modelo usa mais de 100 chamadas a microsserviços para montar uma tela de produtos.
Sim, o tempo é maior, mas basicamente é só o tempo de resolução de endereços (DNS) local, pois os microsserviços estão todos no mesmo datacenter na maioria dos casos. Se é mais rápido pro sistema com um banco monolítico e poucos serviços? A abordagem é válida em cenários como o que eu trabalho, onde temos mais de uma centena de desenvolvedores trabalhando em dezenas de aplicações diferentes que atendem os mesmos clientes.
Minha dica é: comece pequeno. Um banco SQL + um NoSQL, depois vá quebrando e expandindo conforme a necessidade.
Entendi.
Vou procurar sobre essa persistência poliglota. Pq, ao meu ver, mesmo fazendo diversas chamadas, como não resolveremos no banco de dados, muitos dados que serão posteriormente filtrados, irão aumentar o fluxo da rede quando realizamos o JOIN na aplicação;
Sim, com certeza o fluxo de rede aumenta. Logo, você tem de ter um bom motivo para usar essa arquitetura pois ela vai lhe custar mais hardware para que funcione rapidamente. Como toda arquitetura de software aliás, você sempre tem de ter um bom motivo para aplicar, cso contrário gera mais problemas do que resolve.
[…] processo de transformar uma aplicação monolítica em microsserviços é uma forma de modernização de aplicação – algo que os desenvolvedores já fazem há […]