

Não sabe o que é um ORM? O que é o Prisma? Ou até sabe mas não faz a mínima ideia de como usar? Então este tutorial é pra você.
Recentemente escrevi um tutorial sobre como criar uma WebAPI com NestJS, mas que não envolvia banco de dados. Fizemos tudo de forma extremamente profissional e já pensando em futuramente adicionar o suporte a banco de dados. Pois bem, essa hora chegou.
Neste tutorial vamos refatorar o projeto anterior (que avançamos até a parte 3), que você precisa ter feito para conseguir entender esse (a menos que já possua experiência com NestJS), visando adicionar o suporte a banco de dados SQL através do uso de um ORM muito popular chamado Prisma. Também é interessante, embora não obrigatório, que você já conheça algum banco SQL também, sendo que o material recomendado é meu ebook gratuito de MySQL. Usarei MySQL ao longo do tutorial, mas você pode usar tranquilamente outro banco SQL que conheça, como PostgreSQL.
Caso esteja procurando com NoSQL ao invés de banco relacional, pode usar este outro tutorial aqui.
Dito isso, vamos ao tutorial!

#1 – O que é ORM?
Quando estamos construindo aplicações com bancos de dados, independente da linguagem, existem muitas, mas muitas atividades repetitivas mesmo entre sistemas completamente diferentes. Uma delas é a escrita dos comandos e consultas SQL para fazer inserções, atualizações, etc nas tabelas do seu banco e a outra é o mapeamento das entidades e relacionamentos em objetos ou módulos da sua aplicação.
Mapear tabelas para código é um padrão muito comum independente de linguagem ou framework pois te permite programar mais próximo da regra de negócio da empresa, reduz a carga cognitiva de ficar chaveando mentalmente entre as diferentes camadas da aplicação e lhe dá muita produtividade, uma vez que, depois do mapeamento feito, atividades triviais, porém trabalhosas, como ficar escrevendo os mesmos SQLs de sempre se tornam apenas simples chamadas de funções ou métodos.
Ainda assim, fazer este mapeamento na mão também é extremamente penoso e coloca uma curva inicial de trabalho grande em novos projetos. Aí que entram os ORMs ou Object-Relational Mappers.
Um ORM é um framework que lhe permite fazer este mapeamento de forma automática, como o Entity Framework da Microsoft, ou de forma manual, mas extremamente simplificada, como o Hibernate da RedHat, sendo este segundo tipo o mais popular porque muitas vezes a mágica dos geradores automáticos de mapeamento criam código com baixa qualidade e/ou possuem funcionalidades mais limitadas.
Por exemplo, se você tem uma tabela de clientes, você pode ter uma classe ou módulo clientes na sua aplicação e ao invés de escrever um INSERT para salvar um novo cliente na base, você usaria uma função ou método save/add ou equivalente. Assim, você estará manipulando o banco SQL sem precisar escrever SQL de fato, usando apenas a sua linguagem de programação favorita.
Outra coisa bacana de trabalhar com ORMs é que muitas vezes eles atuam com mais de um banco, facilitando portar o seu código para diferentes mecanismos de persistência ou até em cenários de persistência poliglota.
Em Node.js, um dos ORMs mais populares da atualidade é o Prisma.
O Prisma, segundo o site oficial, é um ORM da próxima geração para Node.js baseado em TypeScript, para não apenas diversos bancos SQL como também para MongoDB. Então mesmo que você não use MySQL assim como eu, mas usa qualquer um dos bancos suportados pelo Prisma, deve conseguir adaptar este tutorial para sua realidade.
Entre suas principais características estão o suporte a transações sólidas (ACID), relacionamentos, eager e lazy loading (carregamento adiantado ou tardio), replicação de leitura e muito mais.
Mas antes de começarmos a “brincar” com o Prisma, você vai precisar de um banco de dados criado, faremos isso a seguir.

#2 – Setup do Ambiente
O primeiro passo quando vamos trabalhar com um projeto envolvendo um banco SQL é nos certificar que temos um servidor rodando com um banco de dados à nossa disposição. Caso você não possua nenhum na sua máquina, recomendo o vídeo abaixo onde ensino como baixar e instalar o servidor MySQL.
Depois do MySQL instalado, crie um banco de dados (schema), sendo que o meu o nome vai ser usersdb. Se você nunca criou bancos ou tabelas antes, o vídeo abaixo vai te ensinar os fundamentos.
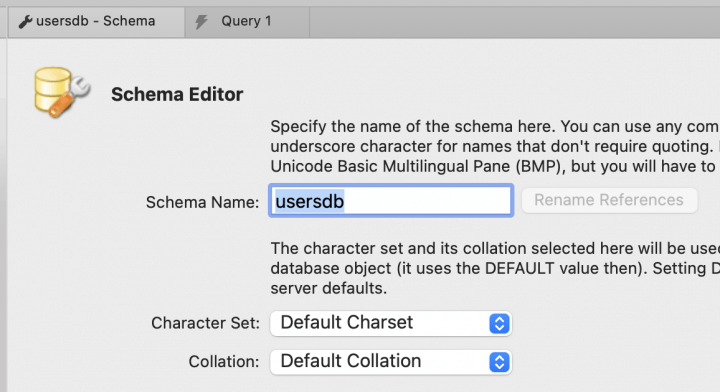
Dentro do banco usersdb, crie uma tabela users com id, name, age e uf, sendo que abaixo forneço o SQL da minha, para você criar igual no seu banco.
|
1 2 3 4 5 6 7 8 |
CREATE TABLE `usersdb`.`users` ( `id` INT NOT NULL AUTO_INCREMENT, `name` VARCHAR(150) NOT NULL, `age` INT NOT NULL, `uf` CHAR(2) NOT NULL, PRIMARY KEY (`id`)); |
Depois nosso próximo passo é ter uma webapi NestJS funcional, para adicionarmos as funcionalidades de banco de dados. Se você não fez o tutorial passado conforme recomendei no início do post, mas já conhece NestJS, apenas crie um novo projeto com um módulo CRUD de users. Abaixo o src/user/user.controller.ts do tutorial passado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import { Controller, Get, Post, Patch, Put, Delete, Body, Param } from '@nestjs/common'; import { UserService, User } from './user.service'; @Controller("users") export class UserController { constructor(private readonly userService: UserService) {} @Get() getUsers(): User[] { return this.userService.getUsers(); } @Get(":id") getUser(@Param("id") id: number): User { return this.userService.getUser(id); } @Post() addUser(@Body() user: User): User { return this.userService.addUser(user); } @Put(":id") replaceUser(@Param("id") id: number, @Body() newData: User): User { return this.userService.replaceUser(id, newData); } @Patch(":id") updateUser(@Param("id") id: number, @Body() newData: User): User { return this.userService.updateUser(id, newData); } @Delete(":id") deleteUser(@Param("id") id: number): boolean { return this.userService.deleteUser(id); } } |
E abaixo o src/user/user.service.ts do tutorial passado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
import { Injectable, NotFoundException } from '@nestjs/common'; export type User = { id: number; name: string; age: number; uf: string; } @Injectable() export class UserService { users: User[] = []; getUsers(): User[] { return this.users; } getUser(id: number): User { return this.users.find(u => u.id == id); } addUser(newUser: User): User { const nextId = this.users.length > 0 ? this.users[this.users.length - 1].id + 1 : 1; newUser.id = nextId; this.users.push(newUser); return newUser; } replaceUser(id: number, newData: User): User { const index = this.users.findIndex(u => u.id == id); if (index === -1) throw new NotFoundException(); newData.id = id; this.users[index] = newData; return newData; } updateUser(id: number, newData: User): User { const index = this.users.findIndex(u => u.id == id); if (index === -1) throw new NotFoundException(); const user = this.users[index]; if (newData.name) user.name = newData.name; if (newData.age) user.age = newData.age; if (newData.uf) user.uf = newData.uf; this.users[index] = user; return user; } deleteUser(id: number): boolean { const index = this.users.findIndex(u => u.id == id); if (index === -1) throw new NotFoundException(); this.users.splice(index, 1); return true; } } |
O src/user/user.module.ts:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import { Module } from '@nestjs/common'; import { UserController } from './user.controller'; import { UserService } from './user.service'; @Module({ imports: [], controllers: [UserController], providers: [UserService] }) export class UserModule {} |
E o src/app.module.ts importando ele:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import { Module } from '@nestjs/common'; import { AppController } from './app.controller'; import { AppService } from './app.service'; import { UserModule } from './user/user.module'; @Module({ imports: [UserModule], controllers: [AppController], providers: [AppService], }) export class AppModule {} |
Com essa etapa finalizada, agora é hora de trabalharmos no Prisma.

#3 – Configurando o Prisma
Nosso próximo passo é instalar algumas dependências e configurar algumas questões mais gerais do projeto. Vamos começar pelas dependências, precisamos adicionar o pacote do Prisma.
|
1 2 3 |
npm i -D prisma |
Com o Prisma instalado, podemos rodar o comando abaixo para inicializar ele em nosso projeto.
|
1 2 3 |
npx prisma init |
Isso vai criar um arquivo .env, que dentro deverá ter a seguinte variável contendo a connection string para seu banco de dados. Neste exemplo, o banco é um MySQL que roda na minha máquina (localhost), na porta padrão (3306) e cujo nome é usersdb. Meu usuário é root e a senha é luiztools (definida na instalação do MySQL), obviamente todos esses parâmetros você tem de mudar conforme a sua realidade.
|
1 2 3 |
DATABASE_URL=mysql://root:luiztools@localhost:3306/usersdb |
O próximo passo é configurar o provedor de acesso à dados no arquivo prisma/schema.prisma, como abaixo (ajuste de acordo com seu banco).
|
1 2 3 4 5 6 7 8 9 10 |
generator client { provider = "prisma-client-js" } datasource db { provider = "mysql" url = env("DATABASE_URL") } |
Agora que configuramos o Prisma para conhecer onde está nosso banco, é hora de fazê-lo mapear nossas tabelas localmente. Fazemos isso com o comando abaixo.
|
1 2 3 |
npx prisma db pull |
Isso vai fazer com que todas tabelas existentes no banco (definido no .env) sejam mapeadas no schema.prisma, como no caso da users abaixo.
|
1 2 3 4 5 6 7 8 |
model users { id Int @id @default(autoincrement()) name String @db.VarChar(150) age Int uf String @db.Char(2) } |
Opcionalmente você poderia criar todo o seu banco a partir de um schema como esse, mas isto é algo que considero um pouco mais avançado, então deixarei para tutoriais futuros.
E por fim, agora você deve rodar o comando abaixo para gerar o Prisma Client.
|
1 2 3 |
npx prisma generate |
O Prisma Client é uma API gerada de maneira personalizada para o seu banco de dados e é com ele que vamos usar o Prisma de fato no projeto.
Importante sinalizar que toda vez que você mexer na estrutura do seu banco de dados, você deve fazer um novo pull e toda vez que mexer no schema.prisma, deve fazer um novo generate.
Com isso terminamos a etapa mais inicial de configuração do Prisma, podemos começar a usá-lo agora.

#4 – Service com Prisma
Quando estudamos os fundamentos do NestJS entendemos que cabe aos services a tarefa de processamento das requisições. No nosso caso, estas requisições irão ler ou escrever no banco de dados apenas, o que torna o nosso serviço um cliente focado no uso do Prisma. Sendo assim, o primeiro passo é ir no user.service.ts e ajustar ele para que se torne um serviço do tipo PrismaClient.
|
1 2 3 4 5 6 7 8 9 10 11 |
import { Injectable, OnModuleInit } from '@nestjs/common'; import { PrismaClient } from '@prisma/client'; @Injectable() export class UserService extends PrismaClient implements OnModuleInit { async onModuleInit() { await this.$connect(); } |
A herança de PrismaClient vai nos dar acesso a uma série de funções específicas do Prisma para acesso à dados, que usaremos já nesse primeiro bloco de código. Já a implementação da interface OnModuleInit permite que a gente crie um script que rodará assim que o módulo for iniciado, na inicialização do sistema.
Esse onModuleInit é implementado logo abaixo, em uma função de mesmo nome cuja única função será inicializar uma conexão com nosso banco de dados. Para fazer esta conexão usamos a função $connect disponibilizada pelo PrismaClient pra gente.
Agora é hora de escrevermos nossas funções usando a propriedade de mesmo nome da tabela: this.users, começando pelas leituras.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
getUsers() { return this.users.findMany(); } getUser(id: string) { return this.users.findUnique({ where: { id: parseInt(id) } }) } |
Ambas são bem semelhantes, com a diferença que a segunda usa um filtro pois queremos apenas um usuário, aquele cujo id seja o passado por parâmetro. Repare que na primeira função usei findMany, pois eram vários usuários a serem encontrados, enquanto que na segunda usei findUnique, pois é apenas um e quero aproveitar o índice da chave primária (maior performance). Outro ponto digno de nota aqui é que o parâmetro id vem como string, pois ele está vindo da URL. É possível ajustar isso, mas foge do escopo deste tutorial, sendo ensinado neste aqui.
Agora vamos escrever as funções de escrita, sendo que só teremos uma função de update desta vez, pois em bancos SQL ela é sempre diferencial, nunca completa (a menos que mude todos os campos).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
addUser(newUser) { return this.users.create({ data: newUser }); } updateUser(id: string, newData) { return this.users.update({ where: { id: parseInt(id) }, data: newData }) } async deleteUser(id: string): Promise<boolean> { await this.users.delete({ where: { id: parseInt(id) } }) return true; } |
Na addUser, usamos a função create que espera uma propriedade data com os dados a serem salvos no banco. Opcionalmente esta função espera uma propriedade select que pode mudar o retorno da mesma (por padrão ela retorna o último inserido).
Na updateUser, usamos a função update, informando no where o filtro para selecionar os registros que serão atualizados, seguido da propriedade data informando os dados que serão atualizados.
E por fim, na deleteUser usamos a função delete, que apenas espera um where com o filtro a ser usado para selecionar os registros a serem excluídos.
Com isso, você tem um exemplo de CRUD completo com Prisma ORM, sendo que não é necessário nenhum ajuste no controller para que funcione com este service. Basta reiniciar seu backend e testar via Postman para conseguir ver que está tudo funcionando.
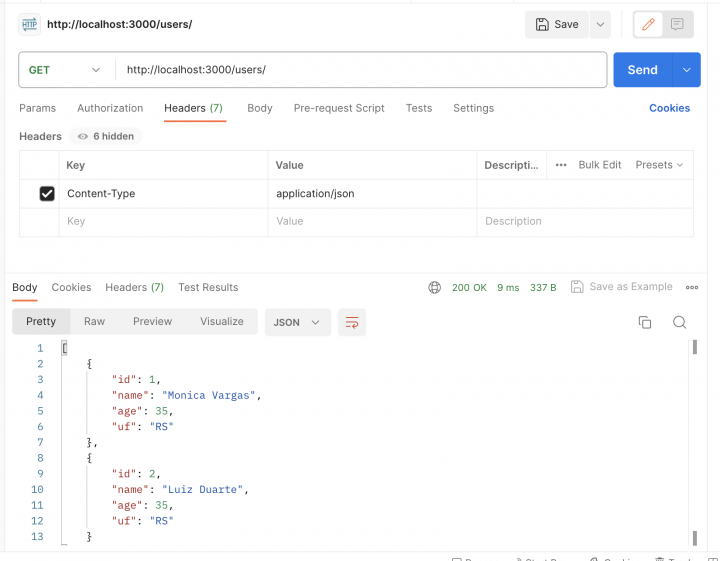
Que tal colocar autenticação nesse projeto? Ensino como neste outro tutorial.
Ou então escrever testes unitários para ele? Ensino neste outro aqui.
Até a próxima!









Olá, tudo bem?
O que você achou deste conteúdo? Conte nos comentários.